
Google affiche dorénavant un message d'information lorsqu'un lien vers une page interdite de crawl est proposée dans ses résultats...
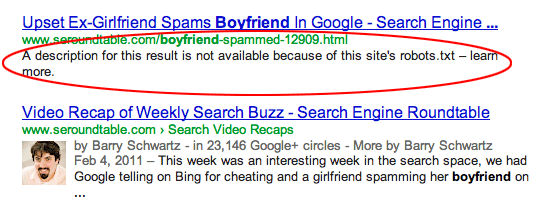
Le site Search Engine Land a constaté que, dans les SERP de Google, un nouveau message "A description for this result is not available because of this site’s robots.txt – learn more" (ou, en français : "La description de ce résultat n'est pas accessible à cause du fichier robots.txt de ce site. En savoir plus") s'affichait dans le "snippet" (texte de présentation de la page) lorsque celle-ci était bloquée par un fichier robots.txt. En effet, si une page est ainsi interdite au crawl par Googlebot, elle peut quand même être présente dans les résultats de Google (même si elle n'est pas crawlée) du fait de liens vers elle depuis d'autres pages web.
Auparavant, ces pages étaient indiquées avec l'URL à la place du titre (la plupart du temps) et sans description. La nouvelle mention fournit donc une information supplémentaire à l'utilisateur du moteur (avec un lien vers l'aide en ligne sur la création et l'utilisation d'un fichier robots.txt)...
 Source de l'image : Search Engine Land |





@Mia : essayez dans un premier temps d’enlever l’espace entre « Disallow » et « : » dans votre fichier robots.txt : « Disallow : /comp_2/crucero/cruceros/costa-croisieres/ » > « Disallow: /comp_2/crucero/cruceros/costa-croisieres/ »
Et ce sur toutes les lignes…
Cdt
Bonjour et merci pour cet article,
J’ai ce souci avec le site http://www.crucerosnet.com
Le message d’erreur apparaît même pour la page d’accueil (et d’autres pages donc)
Pourtant après vérification de la « crawlabilité » de la page sous Google webmaster tools aucun problème ne remonte.
Je ne sais plus quelle piste creuser.
Merci d’avance
Bjr
@ Valais web : voir :
https://www.abondance.com/actualites/20120905-11842-au-sujet-de-google-et-des-robots-txt.html
Bonjour,
Merci pour votre article très intéressant.
Est-ce que la multiplication des résultats de recherche via « site:www.monwebsite.com » avec pour résultat « La description de ce résultat n’est pas accessible… » prétérite le positionnement de mon site dans les pages de résultats de Google ?
Merci pour votre réponse.
Merci de votre réponse. J’ai vérifié les pages dans la partie « Explorer comme Google » des Webmaster Tools, cependant je n’ai trouvé aucune information pouvant m’aider.
J’ai constaté que pour Googlebot il n’y a aucune différence entre les pages affichant le snippet « La description de ce résultat n’est pas accessible à cause du fichier robots.txt de ce site… » et les autres.
@ Paris Annonces : Pour la 1ere question, la partie « Explorer comme Google » des Webmaster Tools devrait vous aider. Pour la seconde, c’est non, il n’y a pas de raisons que Google pénalise ainsi une page ou un site.
Bonjour,
Merci pour cet article. J’ai constaté que les pages principales de mon site ont été mises par erreur dans le fichier Robots.txt et s’affichent sur Google avec le snippet « La description de ce résultat n’est pas accessible à cause du fichier robots.txt de ce site… »
Après correction du fichier Robots.txt, il y a 10 jours, ce snippet s’affiche toujours.
– Est-ce que Google prends en compte les corrections sur Robots.txt, si oui combien de temps faut-il attendre pour que tout revienne à la normale ?
– Peut-il sanctionner une page affichée dans Robots.txt puis retirée ?
@ loran750 : Sur le principe, le robots.txt et la balise meta « robots » noindex sont similaires et doivent donner le même résultats. Cependant, le fichier robots.txt interdit le crawl, alors que pour lire la balise meta « robots », Google doit déjà crawler la page…
Par expérience, je consille toujours le robots.txt plutôt que la balise meta « robots » pour ma part…
Hum.
En même temps, je me pose une question : si on a un robots.txt qui interdit une page, et sur cette page, un « nofollow, noindex », qui a la priorité ?
Parce que ce qui m’intéresse, c’est justement de NE PAS avoir de page listées dans Google (principalement, celles qui sont en DC, celles qui ont des paramètres, …).
Même question pour une page avec une méta « nofollow, index » et « follow, noindex » (si le résultat est différent)
Intéressé par une réponse.
@Annuaire Français : Google n’est pas supposé crawler les pages interdites d’accès par le robot.txt, c’est précisé dans l’article, je cite :
« En effet, si une page est ainsi interdite au crawl par Googlebot, elle peut quand même être présente dans les résultats de Google (même si elle n’est pas crawlée) du fait de liens vers elle depuis d’autres pages web. »
S’il trouve un lien pointant vers une page à l’accès interdit, il référence la destination sans en garantir la teneur.
@ Annuaire Français : non justement, Google indique par ce biais qu’il n’a pas pu crawler la page en question et donc y relever un snippet pertinent…
Très curieuse option de Google, à savoir sur le plan juridique ce que ca vaut, mais Google s’autorise donc a crawler « toutes » les pages d’un site? N’est-ce pas contraire aux recommandations w3c (http://www.w3.org/TR/html4/appendix/notes.html#h-B.4.1)?
D’autant que pour certains sites, cela peut poser de reels problèmes de sécurité…
Il ne reste plus qu’a Google et aux autres sites d’enlever ce fichier robots.txt .
Celui de google (http://www.google.fr/robots.txt ) est conséquent, et celui de Facebook ou Twitter n’aurait donc aucune raison d’être? Affaire sûrement à suivre …
Bonjour,
En vérifiant le fichier robots.txt du site http://www.seroundtable.com/robots.txt, on s’aperçoit effectivement qu’il empêche l’affichage du contenu de l’URL http://www.seroundtable.com/boyfriend-spammed-12909.html.
Cependant, la fonctionnalité de Google est utile si on fait attention à ne pas rendre indexable des URL dupliquées qui, elles, ne figurent pas dans les exceptions du fichier robots.txt.
Dans cet exemple, en faisant la requête »site:seroundtable.com/boyfriend-spammed-12909.html » dans Google, on se rend compte que 4 URL sont indexées dont 2 donnent accès au contenu de la page en question à partir du moteur de recherche.
La question est donc de savoir quelle URL Google va proposer à terme vu qu’une de ces URL qui donne accès au contenu a un presque optimisé et pourrait éventuellement recevoir plus de backlinks ce qui renforcerait son autorité.
Amitiés.