


Lors de sa phase de crawl, le robot Googlebot doit prendre en compte de nombreuses données et informations : redirections (301, 302, 307), robots.txt, code d'erreur 404 ou 410, balise "canonical", balise meta-robot ou directive X-Robots-Tag "noindex", etc. Mais certaines doivent-elles être préférées à d'autres pour otimiser le "budget crawl" du moteur de recherche et obtenir une meilleure exploration ? Une étude nous éclaire ici sur les priorités à mettre en place...
 Par Julie Chodorge
Par Julie ChodorgeDéroulement d'une analyse de logs classique
Traditionnellement, lorsqu'on fait de l'analyse de logs pour le SEO, on procède à un travail de longue haleine en deux grandes étapes. Dans un premier temps, on exporte les logs de Googlebot pour comprendre comment est crawlé et interprété le site, afin d'identifier des facteurs bloquants tels que :
- Des codes réponses ne répondant pas en 200 ;
- Des pages SEO orphelines (absentes du maillage interne) ;
- Des hits (visites de Googlebot) en nombre sur des pages sans intérêt pour le référencement naturel.
Tout ceci a pour but d'analyser la répartition des dépenses du budget de crawl. Suite à cette première étape, s'ensuit la seconde qui consiste à corriger ces facteurs bloquants. Ceci permet d'attribuer le budget de crawl aux pages travaillées pour le SEO, afin de maximiser leur indexation et donc leur référencement.
En effet, chaque site, en fonction de sa taille, de son ancienneté, de son optimisation SEO et de sa thématique, etc. va avoir un certain budget de crawl qui va lui être alloué. Le budget de crawl d'un site peut augmenter ou diminuer au cours de la vie du site.
But de notre analyse : comprendre comment est alloué le budget de crawl en fonction des manières de l'influencer
Le but de cet article est, au-delà de l'analyse de logs et de ce qui fonctionne pour augmenter le budget de crawl, de savoir comment Googlebot interprète les différentes actions mises en place par la personne en charge du référencement naturel. En finalité, nous allons voir ensemble ce qui consomme plus ou moins de budget de crawl et quelles techniques utiliser pour économiser ce budget sur les pages non pertinentes pour le SEO, afin d'en reporter la part la plus importante possible sur les pages travaillées en SEO.
Mise en place de l'expérience
Pour mener à bien cette expérience, nous avons relevé les logs de 12 sites durant 6 mois de manière à obtenir un panel représentatif de ce qui se passe sur des sites de petite et moyenne taille. En effet, on parle souvent d'analyse de logs sur des gros sites, nous voulions savoir ce qu'il en était pour le site de « monsieur tout le monde ». Nous avons donc mixé les logs de 12 sites de différentes typologies : des blogs, des sites vitrine, des sites institutionnels et des sites e-commerce. En termes de taille, cela représente en tout un panel de 202 404 URL pour 7 063 530 hits de Googlebot exclusivement, versions mobile et desktop.
Outils utilisés
- Oncrawl : Crawler SEO et analyseur de logs, payant : à partir de 199€/mois. Un outil assez développé et accessible, mais avec beaucoup de data et un coût relativement élevé. Plutôt pour les annonceurs désirant faire de l'analyse de logs de manière assez développée.
- SEOlyzer : Crawler SEO et analyse de logs, gratuit. Un outil accessible et très rapide et facile à mettre en place. Parfait pour les débutants qui souhaitent tester l'analyse de logs sans avoir besoin d'investir dans un outil coûteux.
- Screaming Frog et Log File Analyzer : Crawler SEO le plus connu et analyseur de logs appartenant à la même solution. Solution payante : £149.00/an pour le premier et £99/an pour le second. Une solution assez rudimentaire qui nécessite d'exporter les logs manuellement avant analyse. Pas d'analyse croisée.
- Excel et SEO Tools : Pour gérer toute la data exportée et récupérer directement dans un classeur Excel les données SEO des différents sites analysés. Solution payante : à partir de 99€ pour un ordinateur. INDISPENSABLE !
Quelles méthodes pour influencer le crawl d'un site ?
Trois familles de méthodes permettent d'influencer le crawl de Googlebot. Ces diverses méthodes sont mises en place sur le site de manière intentionnée ou involontaire. L'important est de bien les contrôler et avoir conscience de leur existence. On recense ainsi :
- Le changement et la suppression d'URL : redirections 301 et 302, erreurs 404 et 410, erreurs serveur 500 ;
- Le blocage d'indexation : balisage Meta Robot Noindex, X-robots-tag Noindex, balisage canonical ;
- Le blocage de crawl : fichier robots.txt.
Au cours de l'analyse, sur l'ensemble des hits, nous avons identifié que les pages en 200 indexables recensaient en moyenne 24 hits par URL. Quand elles reçoivent des liens (internes et/ou externes), ce sont 59 hits en moyenne par URL, et quand elles n'ont pas de lien, 15 hits en moyenne par URL. A partir de là, nous pouvons commencer à comparer le nombre de hits moyen par URL.
Changement et suppression d'URL
Quand une URL est modifiée ou supprimée, en fonction de ce qui est mis en place, elle peut répondre en code 301 ou 302 si elle est redirigée, ou en code 404 ou 410 si elle est supprimée.
Redirections 301
En cas de modification d'une URL, une redirection définitive en 301 permet de notifier le changement aux robots des moteurs de recherche. C'est la solution la plus utilisée en général par les personnes en charge du référencement naturel en cas de modification d'une URL.
Sur l'ensemble des pages, les redirections 301 représentent 37,3% du total, pour 5,3% des hits totaux. Cela nous fait donc une moyenne de 5 hits par redirection 301. Quand on compare avec les pages en 200 indexables, on constate que les redirections 301 sont 5 fois moins hitées que ces dernières.
En revanche, on note un réel impact sur la durée, avec des hits sur des redirections 301 encore 6 mois après leur mise en place. Il faut donc bien les contrôler étant donné leur délai de prise en compte.
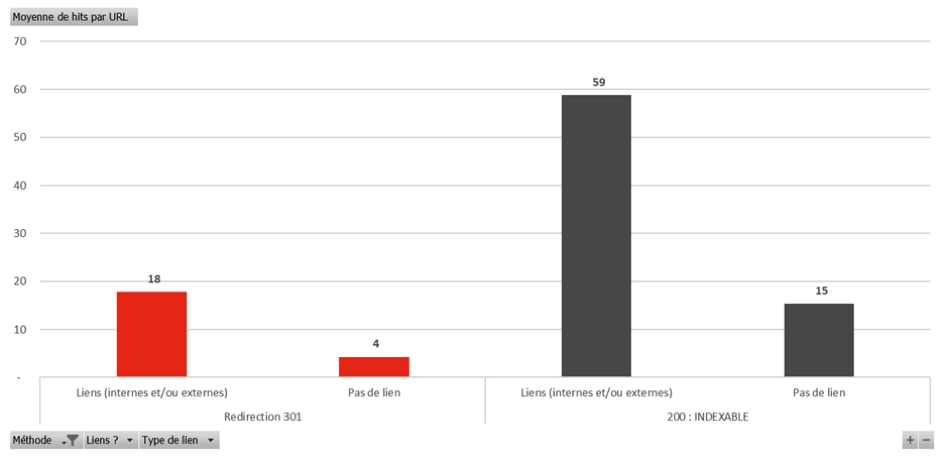
Fig. 1. Moyenne des hits par URL des redirections 301 recevant ou non des liens.
Lorsque les pages qui répondent en redirection 301 ont des liens (backlinks) internes et/ou externes, on note qu'elles sont beaucoup plus hitées que celles sans aucun lien : 18 hits en moyenne contre 4 sans lien.
Redirections 302
En cas de modification momentanée d'une URL, une redirection temporaire en 302 ou 307 permet de notifier le changement aux robots. Ces types de redirections sont utiles en cas de suppression temporaire, dans le cadre d'une page de soldes pour un e-commerce par exemple.
Sur notre panel, les redirections 302 représentent 1,4% des pages totales pour 0,8% des hits totaux, soit 21 hits en moyenne. Les pages en 200 indexables générant 24 hits en moyenne par URL, on constate que les redirections 302 sont presque autant hitées que les 200 indexables. Par rapport aux redirections définitives, les 302 sont 4 fois plus hitées que les 301.
Fig. 2. Moyenne des hits par URL des redirections 302 recevant ou non des liens.
Comme pour les redirections 301, on note que les redirections 302 sont plus hitées lorsqu'elles ont des liens. Il faut donc éviter de faire des liens internes et/ou externes vers des pages qui répondent régulièrement en 302, et ne les utiliser que si on en a vraiment l'utilité. Attention à ne pas confondre leur usage avec les redirections 301.
Erreurs 404
L'erreur la plus fréquente que l'on retrouve sur les sites web est l'erreur 404. Elle correspond à une URL qui a été supprimée ou modifiée et qui n'a pas été redirigée pour autant. En théorie, sur un site parfaitement optimisé en référencement naturel, on ne devrait retrouver aucune erreur 404.
Sur le panel d'URL étudiées, on trouve 4% des pages qui répondent en erreur 404, pour 2,4% des hits totaux. Cela fait en moyenne 21 hits par erreur 404, soit autant que les redirections 302 (21 hits/URL en moyenne) et quasiment autant que les pages en 200 indexables (24 hits/URL en moyenne). On constate que ces URL consomment donc presque autant de budget de crawl que les URL que l'on travaille pour le SEO, il faut donc veiller à ne pas en avoir. Les erreurs 404 n'ont aucune utilité pour le référencement naturel.
Pensez donc bien, à chaque modification ou suppression d'URL, à la traiter soit en redirection, soit en erreur définitive (410).
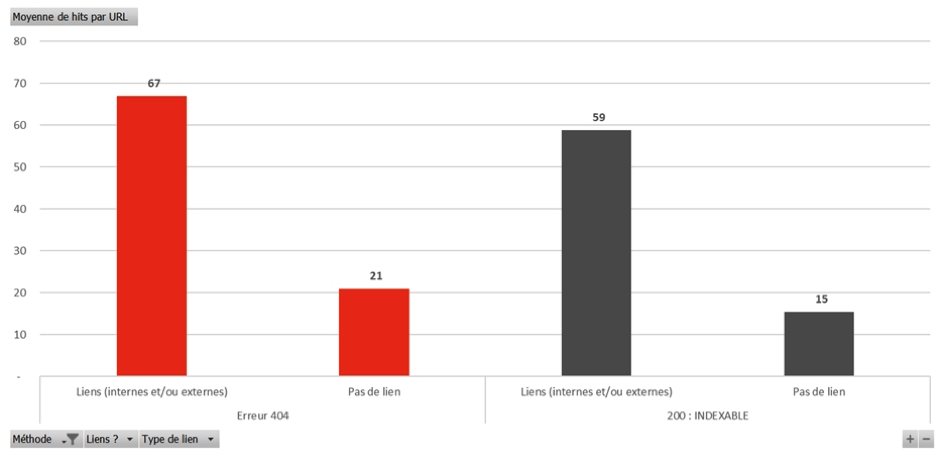
Fig. 3. Moyenne des hits par URL des erreurs 404 recevant ou non des liens
Lorsque les erreurs 404 ont des liens/backlinks (internes et/ou externes), on observe qu'elles sont encore plus hitées que les pages en 200 indexables qui ont des liens : 67 hits/URL pour les 404 avec des liens contre 59 hits/URL pour les 200 indexables avec des liens.
Il faut donc bien veiller à ne pas avoir de lien vers ces pages qui n'ont pas vocation à être travaillées en référencement naturel. Pour les liens internes, étant donné qu'on a la main dessus, il faudra donc veiller à les supprimer du maillage interne. Pour les liens externes, il faudra faire attention à bien mettre en place des redirections 301 afin de ne pas perdre l'intégralité des bénéfices du netlinking.
Erreurs 410
Contrairement aux erreurs 404, les erreurs 410 sont des erreurs définitives. Il s'agit d'une alternative à la redirection 301, qui peut être intéressante à mettre en place en cas de très grand nombre d'URL (pour ne pas alourdir le fichier htaccess et ainsi son temps de chargement) ou en cas d'URL sur lesquelles on ne souhaite pas conserver l'historique SEO (en cas de hack par exemple).
Sur le panel des 200 000 URL, les erreurs 410 représentent 0,7% d'entre elles, pour 0,1% des 7 millions de hits. On compte donc 3 hits en moyenne par page répondant en erreur 410. Ces dernières sont donc 6 fois moins hitées que les erreurs 404 et 1,5 fois moins que les redirections 301.
De tous les codes réponse que nous avons vu pour le moment, les erreurs 410 est donc celui qui est le moins dépensier en budget de crawl. Cette technique sera donc préférable aux redirections 301 en cas de nombre très important d'URL avec peu/pas d'historique SEO. Bien entendu, si c'est une page bien positionnée qui est supprimée, il faudra bien entendu la mettre en redirection 301 plutôt qu'en erreur 410 afin de conserver les positions et l'historique SEO.
Blocage d'indexation
Deuxième manière d'influencer le crawl des robots de moteur de recherche est de mettre en place des implémentations SEO : procéder au blocage de l'indexation. Certes, cela ne bloque pas le crawl, mais une URL qui ne doit pas être indexée ne doit pas consommer trop de budget de crawl, étant donné qu'elle est non pertinente pour le SEO.
Il existe plusieurs manières de bloquer l'indexation d'une page, à savoir : le noindex dans le balisage Meta Robot, le noindex dans le X-robots-tag et enfin le balisage canonical vers une autre URL.
Balisage Meta Robots Noindex
Le balisage Meta Robots se situe dans la section header d'une page HTML et permet d'informer les robots qui crawlent une URL que celle-ci ne doit pas être indexée lorsque la balise indique « noindex ». Ces pages, mises de côté aux yeux du référencement naturel, ne devraient pas consommer trop de budget de crawl.
C'est d'ailleurs ce que l'on note sur l'échantillon observé : pour 0,6% des pages qui ont la commande « noindex » dans la balise Meta Robots, cela représente 1,6% des hits totaux, soit en moyenne 3 hits par URL bloquée à l'indexation via le balisage. C'est donc une bonne solution, qui n'est pas trop gourmande en budget de crawl.
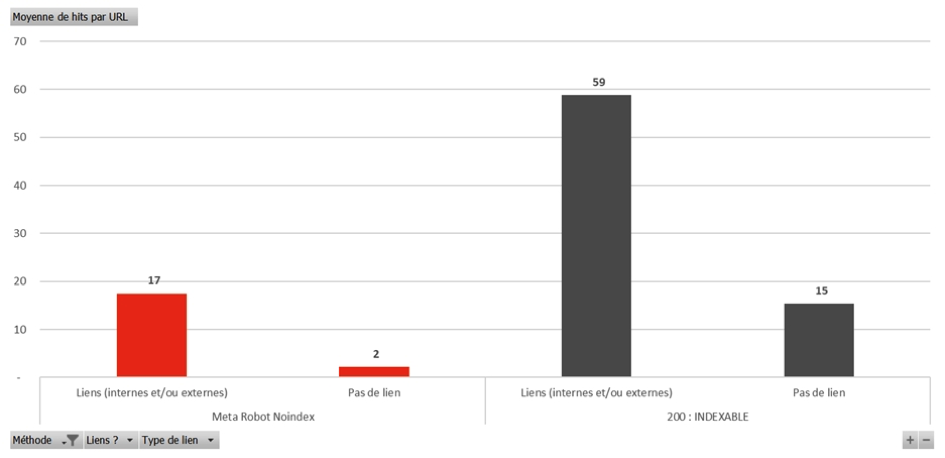
Fig. 4. Moyenne des hits par URL des pages en Meta Robots noindex recevant ou non des liens.
Une nouvelle fois, on note que lorsque les pages ont des liens entrants, que ce soit externes ou internes, elles sont plus hitées que les URL sans lien. En effet, une page en noindex avec des liens sera hitée en moyenne 17 fois par URL, contre seulement 2 fois en moyenne si elle n'a pas de lien.
Il faudra donc éviter les liens externes vers des pages en noindex, d'autant plus qu'elles n'ont pas vocation à se positionner, et éviter de les mettre trop en avant dans le maillage interne. La solution de l'obfuscation, bien que "sensible", peut être une bonne alternative pour ces pages afin de faire disparaître les liens internes.
X-robots-tag Noindex
Une alternative au noindex dans le balisage Meta Robot peut être le noindex dans la section X-robots-tag pour les pages qui ne sont pas au format HTML classique (par exemple, les fichiers PDF ou autres formats). L'instruction donnée à Google est la même, mais d'une autre manière.
En termes de chiffres, ces pages représentent 0,8% des pages totales pour 5,8% des hits totaux, soit 7 hits en moyenne par URL en noindex dans X-robots-tag. Ce type de méthode de blocage d'indexation est donc beaucoup plus gourmand que celui par le biais du balisage Meta Robots avec des URL qui sont 2,5 plus hitées en moyenne.
A choisir entre les deux solutions de blocage d'indexation, il vaut mieux donc préférer la balise Meta Robots pour limiter le crawl sur ces pages et économiser du budget de crawl.
Balisage Canonical
Le balisage canonical permet d'informer les robots des moteurs de recherche de l'URL à référencer. La balise peut être auto-référente si on indique l'URL sur laquelle on se trouve et permet d'éviter toute génération de contenu dupliqué en cas de paramètres dans l'URL. La balise canonical peut aussi indiquer une autre URL, qui a un contenu très proche voire identique; On dit dans ce cas-là que le page est canonicalisée. C'est à ce type de page que nous nous sommes intéressé dans notre analyse afin de savoir si les pages canonicalisées, en théorie non indexables, ne consomment pour autant pas plus de budget de crawl que nécessaire.
Or, tandis que les pages canonicalisées représentent 6% des pages totales, elles regroupent 57,9% des hits totaux, soit la majorité. Cela représente 340 hits en moyenne par URL canonicalisée, contre 24 hits en moyenne pour les pages en 200 indexables. Les pages canonicalisées sont donc 14 fois plus hitées que les pages en 200 indexables, et représentent une énorme dépense en budget de crawl. Attention donc à bien les contrôler pour que celles qui sont en ligne soient vraiment pertinentes et maitrisées.
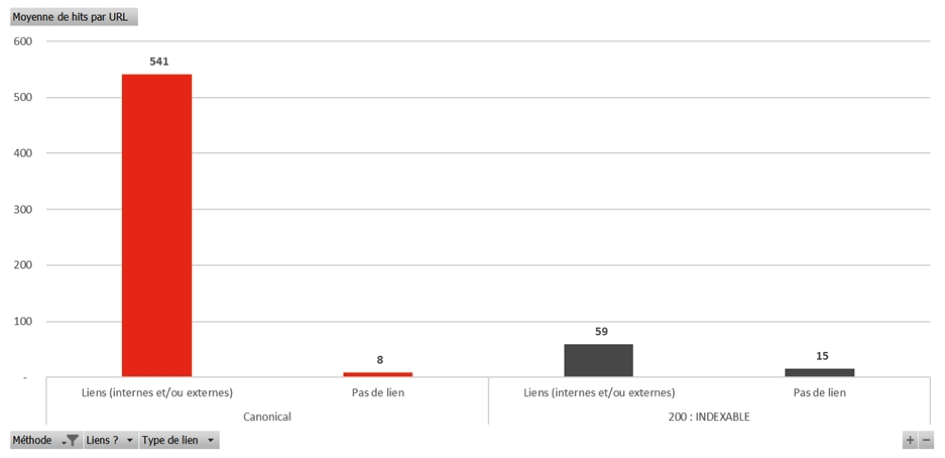
Fig. 5. Moyenne des hits par URL des pages canonisées recevant ou non des liens.
Au niveau des pages canonicalisées, elles sont beaucoup plus hitées quand elles ont des liens entrants. En effet, une page canonicalisée qui reçoit des liens va être hitée en moyenne 541 fois contre seulement 8 fois si elle ne reçoit pas de lien. A ce moment-là, l'équilibre des choses est rétabli puisqu'une page en 200 indexable est hitée en moyenne 15 fois si elle ne reçoit pas de lien.
Il faut donc limiter l'usage des balises canonical, et quand on les utilise, ne pas faire de lien vers ces pages qui n'ont pas vocation à se positionner dans les moteurs de recherche.
Blocage de crawl
Enfin, l'ultime méthode pour influencer le crawl est de bloquer purement et simplement le crawl des robots via le fichier robots.txt. En théorie, les pages dont le crawl est bloqué ne devraient recevoir aucun hit de Googlebot.
Fichier robots.txt
Le blocage du crawl via le fichier robots.txt permet de bloquer l'accès à certaines pages à certains robots, via la directive « disallow ». En général, on bloque l'accès de manière générale à tous les robots à l'aide de *, mais on peut également transmettre des instructions à certains robots en les citant spécifiquement.
Dans le panel d'URL observées, 1,9% des pages sont bloquées via le robots.txt. Or, cela constitue tout de même 3,3% des hits totaux, alors qu'en théorie le chiffre devrait être de zéro. En moyenne, cela représente 2 hits en moyenne par URL bloquée dans le fichier robots.txt. On constate donc que les instructions de crawl ne sont pas toujours respectées.
Malgré tout, de toutes les méthodes abordées, cela reste celle qui est la moins gourmande en budget de crawl.
Petite astuce pour que Googebot respecte les consignes du fichier robots.txt : en plus de s'adresser à tous les robots dans le fichier robots.txt via la commande « User-agent: * », il faut également rajouter des user-agent correspondant spécifiquement à Googlebot, à savoir « User-agent: Googlebot » et « User-agent: Googlebot-image » en recopiant les instructions de crawl. Avec cette technique, on note un meilleur respect des consignes même si les URL sont tout de même crawlées de temps en temps, en moindre proportion.
Conclusion
Sur la figure 6, on retrouve un graphique récapitulatif du nombre de hits moyen par méthode utilisée pour influencer le crawl.
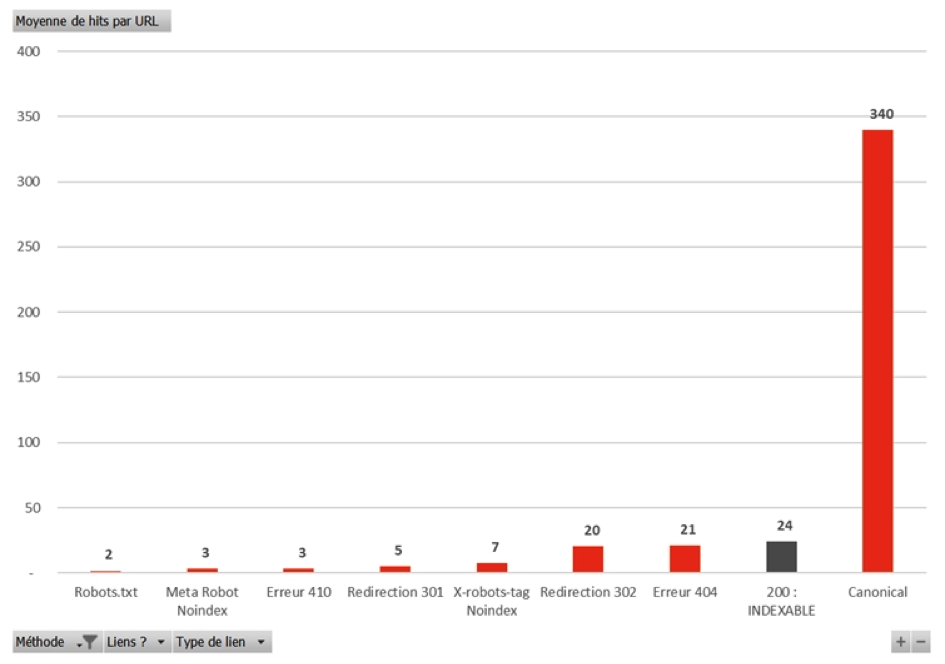
Fig. 6. Récapitulatif des moyennes de hits par méthode pour influencer le crawl de Googlebot.
Les enseignements à en tirer sont les suivants, dans un but d'économiser du budget de crawl :
- Noindex dans balise Meta Robot plutôt que dans X-robots-tag ;
- Erreur 410 plutôt que redirection 301 ;
- Maîtriser les redirection 302 et erreurs 404 qui consomment autant que les pages en 200 ;
- Attention aux pages canonicalisées ! A n'utiliser que comme “rustine” (canonical auto-référente) ;
- Supprimer/Modifier les liens internes et externes des URL non indexables.
Toutes ces recommandations doivent être pondérées en fonction de la taille du site, de sa typologie, de son historique et de sa stratégie SEO.
L'optimisation du budget de crawl entraînera l'optimisation de l'indexation et du référencement, et ainsi donc l'augmentation du trafic naturel.
![]() Julie Chodorge
Julie Chodorge
Consultante SEO chez Korleon'Biz, https://www.korleon-biz.com/.
{kind=link}