






![]()
Lorsqu'on propose sur son site des contenus au format PDF, faut-il en forcer la désindexation auprès de Google ? Est-ce une bonne pratique SEO ? Le déréférencement de ce type de fichier est-il une bonne ou une mauvaise chose ? Réponse...
De nombreux sites proposent en ligne des fichiers PDF, qui sont indexés par Google. Pour les retrouver, on peut taper des requêtes comme "seo filetype:pdf (on recherche ici les fichiers qui contiennent le mot "seo" et qui sont au format PDF) :
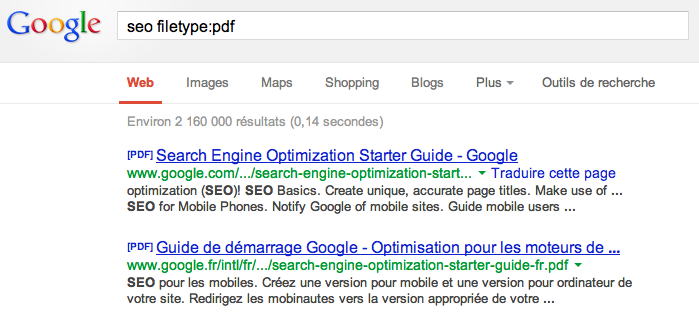 Source de l'image :Abondance |
La plupart du temps, on trouve ainsi de nombreux fichiers à ce format. Google sait donc indexer et lire le contenu de ces fichiers PDF. Mais sont-ils intéressants dans le cadre d'une stratégie SEO ? On peut en effet se poser la question d'une éventuelle désindexation, et ce pour plusieurs raisons :
1. Si Google sait indexer les PDF, ce sont des fichiers qui sont très complexes, voire impossibles, à optimiser. Pas de H1, H2, etc., pas de balises qui indiquent de réelles "zones chaudes" où insérer des mots clés. De plus, la plupart des meta-données que l'on peut rajouter aux PDF ne sont pas lues par Google. Donc, est-il intéressant d'indexer sur Google un contenu non optimisé avec une visée SEO ?
2. Un contenu PDF peut entrer en conflit de "duplicate content" avec le même contenu en HTML, ce qui est dommage. Donc, si vous avez le même contenu dans les deux formats, autant garder l'HTML, plus facile à optimiser, donc à positionner.
3. De plus, lorsque l'internaute trouve, comme dans l'exemple ci-dessus, un fichier PDF dans les SERP de Google, il clique dessus et télécharge directement le fichier. Résultat ? Il n'est même pas venu sur votre site. Vous ne l'avez pas fait "entrer dans la boutique". Avouez que c'est dommage, non ? Ne vaudrait-il pas mieux le faire venir a travers d'un page HTML puis, une fois qu'il est sur le site, lui proposer les différents fichiers PDF à sa disposition ?
Envisager la désindexation des fichiers PDF
Le SEO est souvent affaire d'exceptions. Parfois, il pourra être intéressant de laisser Google indexer les fichiers PDF de son site. Mais il est en tout cas important de se poser la question. Il en est de même, d'ailleurs, des fichiers Word (.doc), Excel (.xls) ou Powerpoint (.ppt) entre autres.
Vous vous apercevrez alors que la réponse penche souvent du côté de la désindexation. En revanche, dans ce cas, les moyens "classiques" de déréférencement ne fonctionnent pas obligatoirement :
- La balise "robots noindex" n'est pas utilisable puisqu'il ne s'agit pas là de fichiers HTML.
- Le fichier robots.txt n'est pas toujours simple à utiliser également car les fichiers PDF ne sont pas toujours, physiquement, dans un même répertoire (comme c'est plus souvent le cas pour les images). Et, dans de nombreux cas, il n'est pas facile de les isoler au travers d'une directive "disallow:".
Deux solutions sont alors possibles :
1. La mise en "nofollow" des liens pointant sur les fichiers PDF et permettant de les télécharger. Cela fonctionnera pour les nouveaux liens (ceux qui n'ont pas encore été suivis par les robots de Google), en revanche, si les fichiers PDF ont déjà été indexés, le "nofollow" sera inefficace.
2. La meilleure façon d'effectuer la désindexation sera alors d'utiliser la directive X-Robots-tag du protocole HTTP en d'envoyer la directive "noindex" lorsque Googlebot tentera de les télécharger. Pour cela, quelques lignes suffiront dans le fichier .htacess de votre serveur Apache (source : l'excellent site Y a pas de quoi) :
#Bloquer l'indexation des fichiers Word et PDF
<files ~ "\.(doc|docx|pdf)$">
Header set X-Robots-Tag "noindex, nofollow"
</Files>
Dans ce cas, les fichiers Word et PDF en question seront désindexés de Google en quelques jours.
Pour conclure, c'est à vous de voir ce qu'il faut faire avec vos fichier PDF. Vous êtes libres, bien sûr, de les laisser indexés, mais le "geste qui sauve" sera avant tout de se poser la question de leur désindexation. Ou pas... Selon la réponse, vous savez en tout cas maintenant comment faire...




Bonjour Olivier, sur un site avec des PDF intégrés sur des pages par iframe et les réponses des PDF avec X-Robots-Tag: noindex, les fichiers mêmes n’appariaient pas dans les résultats de recherche comme souhaité.
Mais est-ce que leur contenu est bien crawlé et contribuant aux mots clés de la page parente (où ils sont intégrés par iframe) ou pas du tout, à votre avis ?
Bonjour Rolf,
Olivier ne travaille plus chez Abondance depuis 1 an et demi, il a pris sa retraite SEO 😉 Voici ce que nous pouvons vous dire à ce sujet : le contenu du PDF n’est pas du tout vu par Google (pas crawlé car derrière un iframe), il ne contribue donc pas au référencement de la page qui supporte l’iframe et donc le PDF.
Bonne journée !
Bonjour Olivier,
Cet article date un peu mais reste d’actualité. Je viens de mettre en place cette directive sur mon site « résilions » dont les fichiers Word et PDF sont indexés par les moteurs.
En revanche, j’ai écrit une variante avec une directive « follow » mais je ne sais pas si c’est une bonne pratique.
Je verrai bien les résultats mais effectivement les internautes et moi-même n’avons à priori pas d’intérêt à ce que les visiteurs arrivent directement sur ces fichiers. En arrivant sur la page html ils peuvent avoir le choix de télécharger un ou plusieurs formats
Merci Olivier sans oublier Aymeric de Y’a pas de quoi
Bonjour Olivier,
Merci beaucoup pour la la directive X-Robots-tag. Je vous confirme qu’elle fonctionne.
Afin d’aider les autres internautes, attention à la balise ouvrante, il faut un « F » majuscule (Files) 🙂
Adrien
Intéressant pour l’idée de l’url canonique lorsqu’il s’agit de contenus identiques, mais lorsqu’il s’agit d’informations complémentaires c’est plutôt déconseillé me semble-t-il.
Dans ce cas la, comment faire lorsque le PDF arrive en meilleure position que la page HTML par laquelle il est possible de télécharger le fichier et que l’on ne souhaite pas désindexer tous les fichiers PDF et perdre par la même occasion les positions acquises ?
Une redirection semble incompatible car l’utilisateur serait dans l’impossibilité de télécharger le fichier à partir de la page web. L’url canonique non plus car les contenus ne sont pas identiques…
Que faire ?
Merci bien pour cet article e, pour moi j’ai bien réfléchi à désindexer les pdf mais après j’ai pris la décision de les laisser pour en tirer un autre avantage des liens qui y sont insérés .
J’ai tendance à privilégier l’indexation de tout les contenus en sachant que l’on peut donner ou pas du poids à un contenu par rapport à un autre (autrefois PR sculpting).
On peut donc influer sur le contenu « leader », tout simplement.
On peut mettre des liens dans les fichiers PDF, Word …
Donc, on réfléchit, on analyse et on fait des choix 😉
Merci pour cet article qui montre bien l’ambiguïté cachée derrière l’utilisation du format PDF.
Merci pour la méthode de désindexation.
J’ajouterai que cette méthode peut être très légitime à mettre en place pour, par exemple, des versions « imprimables » de vos pages. Bien souvent, ces documents sont des PDF reprenant le contenu de votre page sans les éléments environnants (menus, publicité, footer) qui créent tout de même du contenu dupliqué. C’est donc toujours intéressant de savoir comment désindexer proprement les PDF.
Bonjour ! Je dirais que cela devrait dépendre des cas, de l’importance du PDF, etc. En tout cas, cet article fait réfléchir sur le sujet. Merci 🙂 VD
Et pourquoi pas link rel=alternate type=application/pdf … ?
Le problème vient aussi se poser si le pdf représente une notice de montage par exemple, si la personne va dessus sans faire gaffe au site hébergeur, qui nous dit qu’il ne va pas taper le nom du produit la prochaine fois et tomber ainsi sur un site concurrent ?
Le pdf est très intéressant au niveau informations, mais cela peut être à double tranchant
Merci pour l’article Olivier.
@ithonet : c’est 300 pages –> faudra-t-il scroller 300 fois sous prétexte qu’on n’indexera plus les documents ?
Si ton fichier fait 300 pages, je pense – je suis sûr même ! – que tu devras scroller dans le doc .pdf !
@ithonet : Si objectivement il y a un public d’utilisateurs pour lire des documents longs qui ne tiennent pas dans une page HTML pourquoi faudrait-il les désindexer ?
Cet argument n’est pas valable. Les pages web n’ont pas de limite de taille. Un document .pdf, oui (format A4 / A3 / …) !
C’est surtout, qu’un .pdf est souvent plus agréable, qu’une page web. Mais ça, c’est quand on optimise pas les pages web. Les domaines comme l’ergonomie et l’accessibilité sont là pour « corriger » le tire.
Un fichier .pdf doit-être une solution complémentaire, d’accès à l’information. Pas la seule et unique solution.
Dans mes propos, je parle bien de ne pas indexer les .pdf, .doc… je n’ai jamais dis qu’il ne fallait pas indexer les pages qui parlent – voire qui proposent – des documents .pdf.
En clair, il faudrait les désindexer, car :
– Souvent les contributeurs qui postent ces fichiers ne savent pas qu’ils vont se retrouver sur la toile. Et certains posent tout et n’importe quoi (…).
– Les personnes qui utilisent les techniques de « filetype », espèrent trouver des informations… qui au départ semblaient cachées.
– Cela n’importe rien au site qui a hébergé ces fichiers
– Les fichiers sont placés hors-contexte.
Bref. Sujet complexe.
J’ai toujours pris l’habitude de désactiver l’indexation des images et des autres fichiers (.pdf, .doc, …) pour les sites de mes clients… et ce, pour une raison très simple :
Je ne souhaite pas que les informations de mes clients se situent hors-contexte.
Prenons un exemple, d’une société événementielle, pour qui j’ai créé un site. Ils ont des images qui représentent leur activité (son, lumière, …). Si je n’avais pas bloqué l’indexation des images (etc…), elles se seraient retrouvées – certainement – sur Google images via les mots-clés « scène professionnelle événementiel ».
L’intérêt pour mon client : aucun. Car les personnes qui chercheraient ce type d’informations… ne seraient pas qualifiés. En clair : des étudiants, des professionnels qui souhaitent « voler » les images pour leur propre site, …
Autre chose, certaines images pourraient être indexées sous des mots-clés qui n’ont aucun rapport avec l’activité de mes clients. Résultat, des images pourraient se retrouver sous « icone orange » ou autre… car le site est composé d’icônes permettant d’habiller le site.
Là aussi, il n’y a pas d’intérêt pour mon client… car les fichiers sont réellement situés hors-contexte.
Autre point, le mot-clé « filetype: » est surtout utilisé pour faire de la veille et essayer de trouver des informations à droite ou à gauche.
Car, il faut le dire, certaines personnes utilisent Internet comme un serveur géant et ne pensent pas que tout (si on ne fait pas le nécessaire), peut se retrouver le net ! Je pense aux contributeurs lambda qui publient des factures dans le dossier « client » du site de leur société. Bref !
En clair, le filetype c’est plus ou moins une technique d’espionnage. Cela tombe bien, on est en plein dedans…
Pour finir, je ne suis absolument pas d’accord avec @ithonet. Je pense que tu oublies le but premier du web : apporter des visiteurs de qualité et qualifié !
A+
Vous expliquez que vous avez pris l’habitude de le faire très bien et moi aussi. Mais il y a une différence fondamentale et profonde entre « pouvoir désindexer » et « désindexer d’office ».
Tout ne se résume pas au « vol de données » ! Le fond du pb est qu’on en revient au droit de la propriété intellectuelle et que ça n’est pas le sujet. Vous le dites vous-même aujourd’hui si vous ne voulez pas voir figurer un document sur le web vous pouvez faire en sorte qu’il n’y soit pas ! En revanche, interdire par la désindexation l’accès aux contenus, c’est MAL !!! Quid des étudiants qui publient leur thèses en ligne, des gens qui téléchargent des cours MIS A LEUR DISPOSITION par des gens qui croient à l' »open-source ». C’est peut être un peu surréaliste aujourd’hui mais le WEB a aussi pour but la vulgarisation et la libre distribution des connaissances SI L’ON VEUT ! A mon sens le problème n’est pas technique ou liées à de bonnes pratiques mais ETHIQUE !
On mélange un peu tout là…
@ithonet : Mais il y a une différence fondamentale et profonde entre « pouvoir désindexer » et « désindexer d’office ».
Tu as tout à fait raison. Il est vrai qu’il est plus complexe de désindexer un fichier déjà présent sur le web, plutôt que de bloquer l’indexation dès le départ.
@ithonet : En revanche, interdire par la désindexation l’accès aux contenus, c’est MAL !!!
Non ! Ce qui est mal, c’est de ne pas rendre accessible ces informations au format standard (xhtml).
Combien de sites de collectivités locales proposent sur leurs pages « accès / horaires » des fichiers en .pdf en dl et comme contenu pour la page « télécharger nos horaires d’ouverture » ?
Le vrai problème vient du fait que le fichier aurait du-être disponible en complément et pas en temps que contenu unique.
Le contenu web est à l’origine fait de liens et de pages web… pas de fichiers .pdf.
Donc, je réitère il faut bloquer les fichiers qui pourraient être placés hors-contexte, mais offrir l’accès à ces contenus (si on le souhaite !), de façon accessible.
A+
@taskone ok pour les contenus HTML je suis d’accord mais parfois le pdf/word/excel, est plus approprié : un essai, une matrice de tableur, un cours, un thèse, une notice… c’est 300 pages –> faudra-t-il scroller 300 fois sous prétexte qu’on n’indexera plus les documents ?
Le problème c’est que ça pose la légitimité du contenu et qui doit choisir ? Si objectivement il y a un public d’utilisateurs pour lire des documents longs qui ne tiennent pas dans une page HTML pourquoi faudrait-il les désindexer ?
@gpeyronnet : bien vu, c’est une autre solution. Possible uniquement dans le cas d’un éventuel duplicate content PDF/HTML, en revanche. Je vais l’ajouter dans l’article. Merci !
cdt
Désindexer via un noindex ? Et pourquoi pas plutôt un canonical dans l’entête http ? 😉 Qui renverrait bien sûr vers un contenu similaire à celui du PDF, mais au format html.
Tout à fait d’accord !
Je pense qu’il faut aussi réfléchir en termes de « search experience ». Et en ce sens, les PDF, en étant isolés du reste du site web, ne sont pas top pour l’utilisateur.
A l’origine du modèle pensé par Tim Berners Lee, le WEB est un réseau de données connectées ! Données –> Pas seulement de sites ! C’est quand même incroyable qu’on ne considère plus le Web qu’au travers des sites !
La question a plusieurs angles :
– la difficulté de l’internaute à aller plus loin que le contenu du PDF
– la possibilité pour vous de l’accompagner (dans le cadre d’un site commercial)
– le SEO
Eh bien moi ce qui m’embête c’est que ça commence à entrer en contradiction avec beaucoup de choses sous couvert de bonnes pratiques SEO et de duplicate content. A mon sens ça s’apparente un peu plus à un petit « arrangement entre amis » sur les droits d’auteurs ! Les PDF sont utiles et indispensables à l’utilisateur ! On peut y trouver des ressources en tous genres : thèses, cours, essais, notices… on peut aussi y distribuer un contenu CHOISI PAR L’UTILISATEUR, plus long que sur le web –> le bénéfice en terme de notoriété de fait étant alors le même que celui d’un site (éditeur tout au moins) : les utilisateurs s’abonneront peut être à une newsletter ou iront voir quel AUTRE contenu est disponible sur votre site ! Il y a un côté très « open source » dans l’idée de mettre des pdf à dispo ()… bref j’ai l’impression qu’on confond « concordance des occurrences de l’utilisateur » et indexation c’est dommage…