







Google ne donne pas accès à une option de téléchargement exhaustif des URL indexées pour un site web donné par le moteur de recherche et ses robots. Pourtant, cette donnée serait si importante et utile, avant tout pour le moteur lui-même, d'ailleurs. Alors, pourquoi ne pouvons-nous pas obtenir ces informations ?...
Tous les webmasters s'intéressant un tant soit peu au SEO (et d'autres certainement) connaissent la syntaxe d'interrogation "site:" sur Google (exemple : [site:www.abondance.Com]). Elle permet d'obtenir approximativement le nombre d'URL d'un site donné qui sont indexées par Google. Dans le temps, Google proposait les 1 000 premiers résultats. Aujourd'hui, il s'arrête le plus souvent à 500 ou 600, parfois moins. Impossible donc, dès que votre site commence à grossir, d'obtenir par ce biais une liste exhaustive des URL indexées.
Il existe bien un autre moyen via la Search Console avec l'option "Trafic de Recherche > Etat de l'Indexation". Ce graphique (voir illustration ci-dessous) donne des indications globales, souvent plus précises que par la syntaxe "site:", sur ce nombre total de pages indexées, avec une notion d'historique sur les 12 derniers mois. Cette fonction est souvent très utile pour voir si un incident d'indexation n'a pas eu lieu à un moment donné, ou lors d'une migration avec changement d'URL, etc. Mais, là encore, si les données brutes du graphique sont téléchargeables, aucune option ne permet d'obtenir la liste des URL indexées de façon exhaustive.
Alors, oui, on peut obtenir un résultat plus ou moins bon avec plusieurs requêtes de type "site:" sur plusieurs zones du site (sur des répertoires notamment), mais c'est fastidieux et cela reste surtout du bidouillage peu fiable et ne s'adapte pas à des gros sites de plusieurs milliers de pages. Et surtout, rien ne dit que le résultat sera exhaustif (puisque la requête "site:" ne l'est pas, notamment lorsqu'il y a des redirections 301 qui ont été mises en place)...
Une si précieuse liste d'URL indexées...
Pourtant, cette information serait sacrément utile pour les webmasters qui pourraient ainsi mieux gérer leur site web et la façon dont Google le "digère". Voici quelques exemples (liste loin d'être exhaustive) :
- Détection et nettoyage (désindexation) d'URL de pages proposant des contenus de faible qualité (critère Panda).
- Détection facilitée de duplicate content intrasite.
- Visualisation de différences entre les pages indexées par Google et celles réellement dans l'arborescence (liste que l'on peut récupérer avec des outils comme Screaming Frog, OnCrawl ou Botify entre autres).
- Vérification de l'indexation des URL soumises via un Sitemap XML.
- Détection et suppression de pages anciennes et obsolètes, toujours indexées par le moteur.
- Suivi d'une migration avec changement d'URL.
- Etc.
Encore une fois, cette liste est loin d'être exhaustive. Le plus étonnant est que toutes ces actions aideraient grandement Google à nettoyer son index en ne lui donnant à crawler que des URL correspondant à des contenus de qualité. N'est-ce pas là le but ultime de filtres algorithmiques comme Panda, Phantom ou autres Quality Updates ? Alors, pourquoi le moteur ne propose-t-il de télécharger ces données ?
Quelques raisons (plus ou moins valables)...
On peut imaginer plusieurs raisons qui font que Google ne donne pas accès à ces informations :
- La taille du fichier à télécharger : il est clair que pour des sites comme Amazon.com (1 milliard de pages indexées) ou, plus près de nous, Cdiscount.com (17 millions), cela peut poser des problèmes de dimensionnement. Mais enfin, ce sont également là des cas extrêmes. On pourrait imaginer une limite (par exemple 10 000 URL représentatives) et, pourquoi pas, une option payante pour en obtenir plus si nécessaire ? Ceci dit, une première limite à 10 000 URL résoudrait déjà de nombreux problèmes pour des sites en-dessous de cette taille (et ils sont légion).
- La possibilité de spam. Souvent, Google ne donne pas accès à une information par peur que cela génère du spam contre son moteur ou que cette donnée ne soit détournée pour des raisons de malveillance. Mais en quoi le nombre d'URL indexées par un site et leurs intitulés, disponibles uniquement pour le webmaster du site qui plus est, peuvent-ils être utilisés pour spammer Google ? Il faut avouer qu'on cale à ce niveau...
- Une volonté de ne pas aider (trop) les webmasters. Pourquoi pas, mais dans ce cas, Google se prive d'une option qui nettoierait son index sans rien faire de son côté (manoeuvre dont il est coutumier). Un peu étonnant, non ?
Et vous, quel est votre avis à ce sujet ? Cette donnée vous serait-elle utile ? Pour quoi en faire ? pouvez-vous nous donner quelques exemples ? Et pourquoi, selon vous, Google n'y donne pas accès ? Vous avez la parole dans les commentaires !
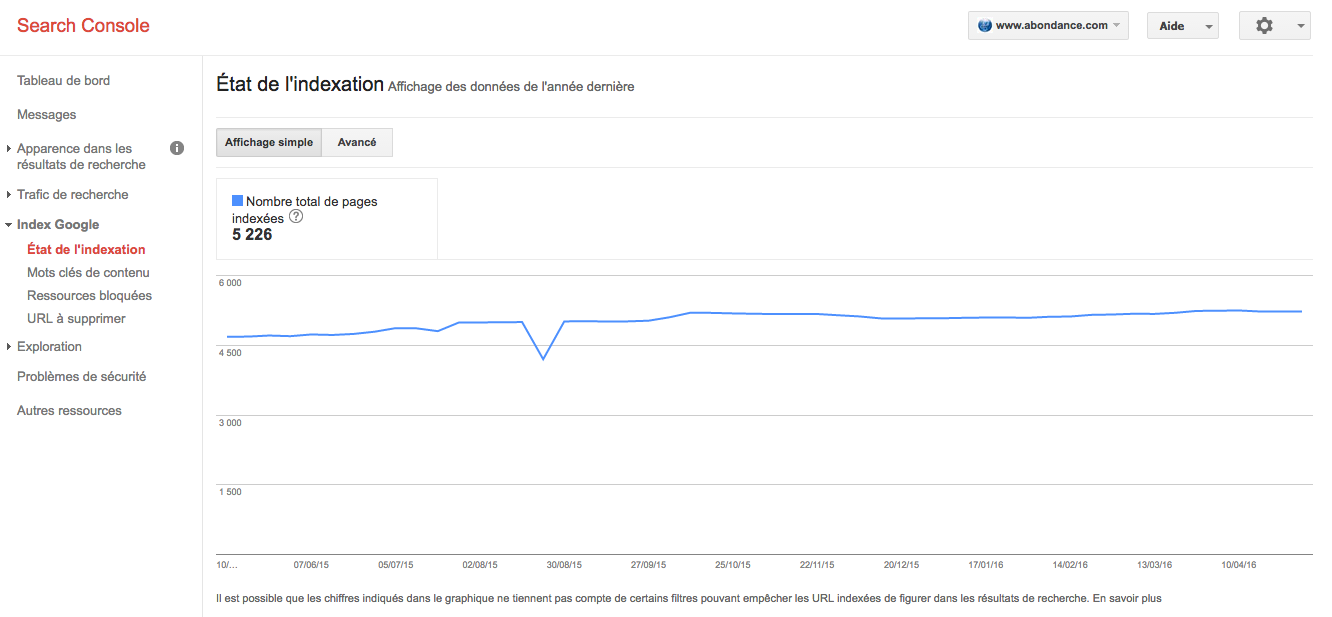 L'option Trafic de Recherche > Etat de l'Indexation de la Search Console... Source de l'image : Google |



Bonjour
Je me pose la question depuis plusieurs années.
Je vous propose l’idée suivante et vous remercie pour vos retours.
Puisque Google enregistre les pages dans son index et dans son cache il est régulièrement obligé de tester leurs actualités sur le site concerné et donc d’envoyer des requêtes.
Enregistrer toutes les requêtes dirigées vers le site du bot Google ne permettrait t’il pas d’obtenir avec une certaine précision la liste des url enregistrées par Google.
Merci pour votre retour
Malheureusement non car le fait que Googlebot crawle une page n’est pas une garantie qu’elle soit indexée… 🙁
La technique de Mathieu n’est pas assez intéressante, car vous aurez uniquement l’info des urls que vous avez renseigné. Or il y a des urls avec paramètre, des urls auto-généré etc … qui passent donc à la trappe.
En effet, Polo, ma technique n’a rien d’un remède miracle, mais juste d’une solution possible pour se rapprocher de la réalité. Pour les URL auto-générées je ne vois pas le problème (car on peut appliquer la même astuce via des « hooks », etc.), seules les URL avec paramètres peuvent être problématiques (sauf si elles sont également intégrées dans des Sitemaps, ce qui est autorisé). Disons qu’aucune technique n’existe, alors cherchons ce qui peut être le mieux, je suis ouvert à tout. 😀
Alors là bravo ! Je n’avais pas vu d’article semblable! On s’est déjà tous posé cette question sans pour autant en rédiger un article compréhensible de tous.
ça c’est du contenu pertinent et frais. Bon ceci dit, pour en revenir au sujet traité, je trouve que c’est fort dommageable de ne pas avoir cette possibilité depuis la Search Console.
Quand à la technique de Mathieu, c’est super chaud !! je ne me vois pas faire une chose pareille….
Je comprend que les pros du référencement soient intéressés par cette question et réponse.
Mais, est-ce vraiment crucial d’avoir cette données ? Réfléchissons ensemble:
— une page est indexée, elle est dans le cache. Mais, la date du cache date du 3 septembre ou du 6 juin 2015. Peut-on encore parler d’indexation ?
— une page est indexée et son cache date du 3 mars 2016, mais elle n’apparaît sur aucun mot clé dans les premières pages des SERPs. Peut-on parler d’ indexation ?
— vérifiant souvent des liens morts d’une base de données, je vois aussi des résultats différents selon l’outil utilisé: la commande cache dans le moteur, la même commande cache qui était insérée jusqu’il ya peu dans le bouton PR de la google barre (qui pourtant est la même commande), le cache via la commande info, ou encore chercher avec guillemets une phrase de la page dans google search. Donc, google lui-même s’en mêle les pinceaux.
Bref, alors que par définition, l’indexation est un concept de type oui ou non, cela ne semble pas être ainsi chez Google.
D’ailleurs je n’ai jamais compris pourquoi dans Google search console, un site peut par ex passer de 100.000 pages indexées à 70.000 six mois plus tard puis remonter à 85.000 encore x mois plus tard (ou les mouvements inverses) sans que cela ne s’explique par des changements dans le site (ni par des problèmes de crawl ou similaire) .
Bref, même la statistique globale affichée n’est pas fiable. C’est peut-être pour cela que Google n’en donne pas la liste. Vous imaginiez un moteur parfait où tout est scientifiquement analysé et chiffré alors que vous découvririez ainsi tous les rebuts remisés dans l’arrière boutique.
Par analogie, pensez au duplicate content que Google a annoncé il y a 6/7 ans vouloir éradiquer des SERPs au point que tout webmaster/ référenceur consciencieux s’en préoccupe à juste titre . Et pourtant, les SERPs en contiennent encore beaucoup et , dans les recherches en trant qu’internaute ordinaire, je vois même bien se classer de nouveaux sites qui font des compilations de contenus d’autres sites.
> une page est indexée, elle est dans le cache.
> Mais, la date du cache date du 3 septembre ou du 6 juin 2015.
> Peut-on encore parler d’indexation ?
Oui bien sûr. Une page non mise à jour (une biographie de Voltaire par exemple) est-elle obligatoirement non pertinente ? Je ne pense pas. Toutes les pages web n’ont pas vocation à répondre à des requêtes « chaudes ».
> une page est indexée et son cache date du 3 mars 2016,
> mais elle n’apparaît sur aucun mot clé dans les premières pages des SERPs.
> Peut-on parler d’ indexation ?
Oui. Et de mauvaise optimisation aussi 🙂
Pour le premier cas cité, le cas d’une biographie de Voltaire inchangée depuis des années, le fait que le contenu ne change pas n’empêche pas Google de mettre à jour son cache.
Test fait: un discussion d’un forum de décembre 2002 avec seulement une petite page et à peine quelques réponses sans utilité réelle, la dernière datant de décembre 2002. Le cache date de février 2016. OK c’est bien indexé
Mais si le cache datait de deux -trois ans, je me demanderais quand même sur le sens à donner au mot indexation. Google donnerait-il dans ses résultats une page dont il ne sit même pas si elle existe encore au moment de la requête.
Quant au deuxième cas, c’est exactement ce que je veux dire. Indexation, c’est oui ou non; mais chez google , quelle différence y a-t-il entre une page non indexée et une page indexée à très faible PR (je parle ici du « vrai » PR)..
C’est comme des températures de +0,1° et – 0,1°, d’un côté il ne gèle pas, de l’autre, oui; mais en pratique c’est quasi la même chose.
Une page non indexée, cela peut aussi être une page mal optimisée.
Dans l’indexation, il y a in fine une partie « grise » qui n’est pas significativement différente de la non indexation. D’où d’ailleurs les différences entre le moyen technique utilisé pour vérifier cette indexation. Et cela explique aussi EN PARTIE les fluctuations du nombre total affiché des pages indexées (je parle ici de sites de plusieurs dizaines de milliers de pages indexées).
Hello Olivier,
Il y a peut-être un moyen, assez fastidieux, certes, de voir les URLs indexées. De base, le moteur indexe toutes les pages qui ne lui sont pas interdites par le robots.txt ou par les pages en noindex (qui souvent sont les mêmes).
Il existe des outils qui permettent de récupérer l’ensemble des URLs du site (avec leurs métas, descriptions, etc.), sans distinction. Il faut ensuite retirer de cet ensemble les dossiers ou pages bloquées pour les moteurs, et on a une bonne vue d’ensemble.
En mettant en place une corrélation entre les données fournies par la Search Console, le robots.txt et ces URLs brutes, on peut avoir quelques données utilisables je pense. Le boulot de SEO, c’est beaucoup de l’analyse constante ^^
Bien entendu, cette méthode a de nombreuses limites, je le concède. Je pars du principe que si une page a été indexée, elle peut rester dans le cache, mais Google luttant de façon drastique contre les fraudes et les black-haters, il aura très rapidement retiré de l’index (et donc du cache, les deux sont intimement lié à mon sens) toutes les pages indésirables…
Mais je suis un amateur, je peux me tromper !
Hello. Ca ne fonctionne malheuresuement pas ainsi. Ca voudrait dire qu’il n’y a dans l’index de Google que les pages présentes dans l’arborescence. Or c’est la plupart du temps faux. Voir mes commentaires précédents…
Pour moi, c’est un des grands manques par très compréhensibles du côté de Google. La seule astuce la plus viable que je connaisse est de jouer avec des centaines de sitemaps XML et un sitemap index.
En gros, on créé des sitemaps XML avec seulement 1 à 3 URL dedans, tous reliés à un sitemap index. Comme la Search Console indique le nombre d’URL indexées par sitemap, ça permet de suivre et de savoir à peu près lesquelles sont prises en compte, mais c’est horrible à mettre en place. 😀
Va faire ça avec un site de 100 00 pages 🙂
Oui mais tu es un homme de challenge, donc ça passe. 🙂
Plus sérieusement, je pense qu’on peut automatiser ça (un plugin qui créé un sitemap automatiquement à chaque création de page par exemple et qui l’ajoute dans un sitemap index). C’est chaud, mais faisable.
Avec les logs et GA, on peut connaitre le volume de pages actives par typologies de pages. Chiffres ensuite à comparer avec le volume réel sur le site et le volume de pages crawlées. Certes on n’aura pas le nombre exact de pages indexées, mais plutôt une tendance, ce qui sur des sites à forte volumétrie me parait déjà suffisant.
« il faudrait extraire des logs les URL crawlées sur un an par Googlebot et voir si elles sont dans le cache, le tout sur un an (pour avoir un crawl fiable de Google) »
rooo.. ce serait un bel outil ça ! on envoie les logs d’un an de d’un site … et l’outil fait son petit boulot d’extraction ET DE COMPARAISON… et comme dit aurélien ça répondrait sûrement à la question posée ici ! 😀
je suis pas dev.. sinon je l’aurai mise en marche 😀
Et pour compliquer les choses : comment avoir une liste complète des urls qui sont dans l’index secondaire ?
Parce que, officiellement, l’index secondaire n’existe pas, dixit Google 🙂
Bonjour,
La syntaxe « site:URL » permet également de détecter des mouvements au niveau de l’indexation. Cela peut permettre par exemple de découvrir que le robot teste toutes les dates vides d’un calendrier et de voir que le volume rechute ensuite après la mise en place d’un correctif sur la rubrique du calendrier.
Je vous remercie, des informations très intéressantes et utiles
Bonjour Olivier,
Mais si on peut 🙂
Dans la mesure où le(s) site n’utilise pas de noarchive/nocache dans ses entêtes HTML, il y a un autre moyen de checker l’indexation des pages. Certes, ce n’est pas 100% fiable, mais bien plus que SC, ou un scrap du résultat d’un site:domaine.com :
Avec la commande cache:url, si on obtient quelque chose, on a de bonnes raisons de penser que la page est indexer. Juste ? Il suffit alors de récupérer la liste complète des URLs du site avec un crawler (Screaming Frog par exemple), et de checker ensuite si chaque URL est en cache de Google, avec Scrapebox. Cela nécessite bien sûr des proxies !
Non 🙂 Car, comme indiqué dans l’article, un crawler comme Screaming FRog donne la liste des URL dans l’arborescence mais pas les URL indexées par Google. J’ai l’exemple d’un site qui avait 10 000 URL crawlées par Screaming Frog mais qui avait en fait 200 000 URL indexées : vieiilles pages, bugs, etc. Bref, les crawlers type SF, Botify ou OnCrawl, c’est super, mais ça ne donne pas une idée exhaustive des URL indexées par Google…
A la limiite, il faudrait extraire des logs les URL crawlées par Googlebot et voir si elles sont dans le cache, le tout sur un an (pour avoir un crawl fiable de Google). Mai sc’est vraiment une usine à gaz… 🙁
Alors effectivement tu as raison pour l’obtention de la liste complète des URLs dans l’index, de l’autre ça permet quand même d’avoir si les URLs « en prod » sont indexées ou pas.
Très bonne idée également de concaténer URLs trouvées dans les logs + URLs du crawl screaming Frog. Ca fait faire un peu de tambouille, mais j’aime bien l’idée qui est sans doute le meilleur moyen d’avoir un résultat le plus exhaustif possible.