







Vous avez peut-être parfois besoin de copier/coller simplement, pour une requête donnée, les résultats de Google (titre + description + URL) dans un dossier à telle ou telle occasion et de façon ponctuelle. Si vous voulez vous éviter une fastidieuse et répétitive opération manuelle, les solutions disponibles ne sont pas si courantes finalement. En voici deux sous forme de tutos...
Pour un client, j'ai dernièrement dû réaliser un dossier qui récapitulait les différents résultats ("liens bleus") renvoyés par Google sur plusieurs requêtes les concernant. Il me fallait donc récupérer (on parle dans ce cas de "scraper") les différentes informations de la SERP pour les recopier facilement dans mon dossier sous Word : titre des liens, URL et description textuelle qui forment le "snippet" cher à Google.
Il ne m'a pas fallu beaucoup de temps pour m'apercevoir que ce n'était pas si simple que cela et que peu d'outils, finalement, proposaient ce type de fonctionnalité (un certain nombre d'outils proposent de récupérer facilement Titre et URL, mais très peu la description du lien). Bref, un passage par les réseaux sociaux (merci encore à toutes les personnes ayant contribué à cette recherche et mention très spéciale à Fabrice Valtancoli et Sébastien Billard pour les deux techniques évoquées ci-dessous, et qui pourront vous aider si vous avez à affronter un jour la même problématique :
Première possibilité : installer la Mozbar (sur Chrome ou Firefox). Puis, une fois l'outil installé dans votre navigateur, vous allez sur Google et lancez la requête désirée. Cliquez ensuite sur le pictogramme de téléchargement :
 Pictogramme de téléchargement dans la Mozbar. Source de l'image : Abondance |
Vous récupérez ainsi un fichier CSV avec les données désirées. Vous allez alors dans Google Docs / Speadsheets et vous importez (menu "Fichier > Importer" puis onglet "Importer" dans la fenêtre qui s'ouvre) le fichier en question. Un menu s'ouvre et vous le validez :
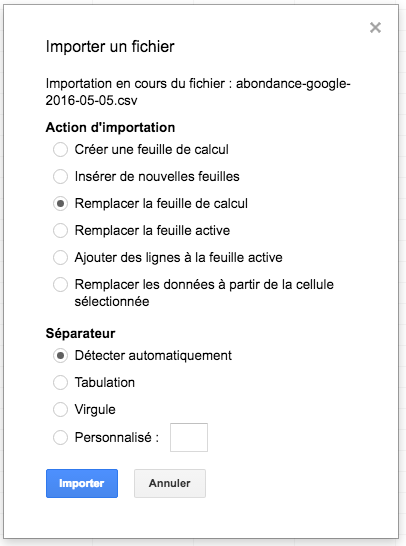 Menu d'importation du fichier CSV dans Google Docs. Source de l'image : Abondance |
Et le tour est joué : vous avez sous les yeux chaque champ désiré (et même un peu plus) et il ne vous reste plus qu'à faire un copier/coller de ce qui vous intéresse :
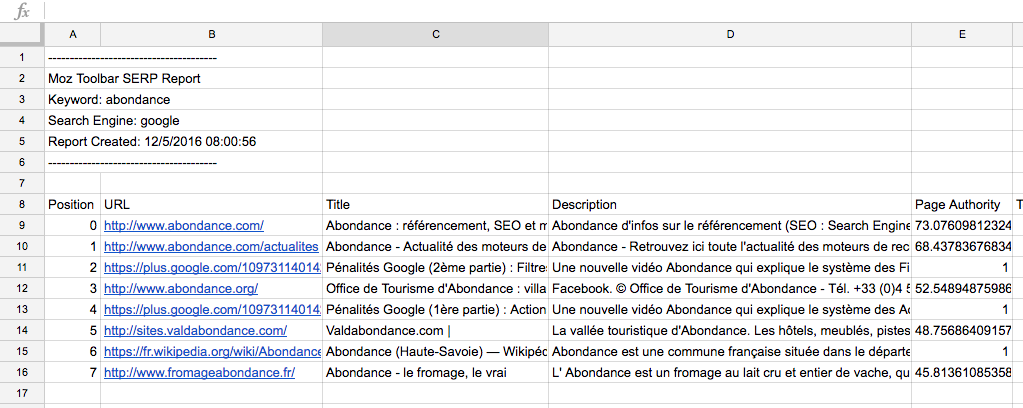 Les champs obtenus sont maintenant disponibles. Source de l'image : Abondance |
Seconde possibilité : utiliser l'extension Scraper pour Chrome qui, par défaut, ne fonctionnera pas, mais grâce à Sébastien Billard, vous pourrez la configurer pour que cela marche parfaitement. Une fois l'extension intégrée dans votre navigateur, vous faites un clic droit n'importe où dans la SERP et vous optez, dans le menu contextuel, pour le choix "Scrape Similar..." :
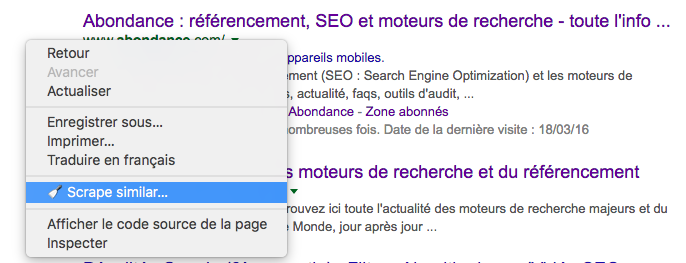 Option "Scrape Similar" sur un clic droit dans la SERP. Source de l'image : Abondance |
Et si vous suivez bien les directives de l'ami Sébastien, vous obtenez également les infos demandées :
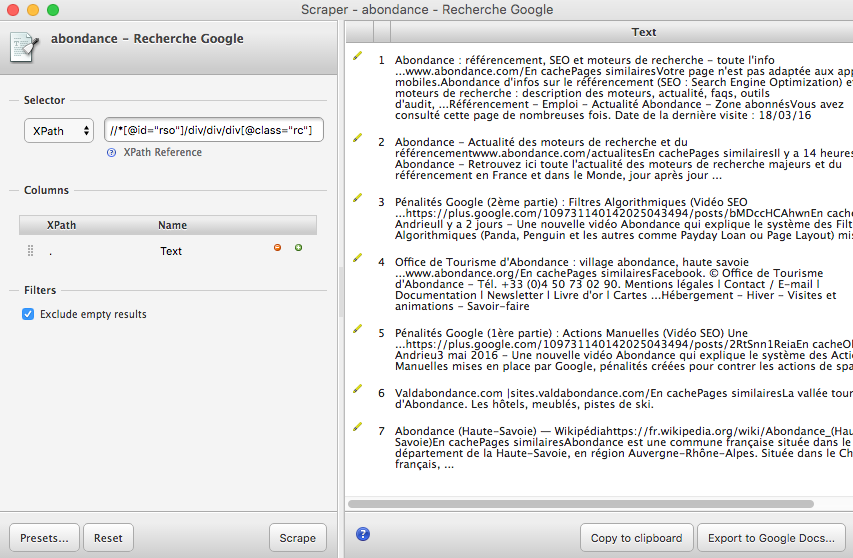 L'extension Scraper vous fournit les données désirées de la SERP. Source de l'image : Abondance |
Alors, quelle option choisir ? La première ou le seconde ? Pour ma part je préfère la première, qui donne un résultat plus "propre" (Scraper renvoie les termes comme "En cache" ou "Pages similaires" par exemple, et nous avons eu un peu de mal avec les retours à la ligne proposés). La pérennité de la deuxième par rapport au code des SERP Google qui changent tout le temps peut également poser question. Mais n'hésitez pas à tester les deux pour voir celle qui vous convient le mieux.
Sinon, bien sûr, vous avez des outils comme Rddz Scraper mais ils conviennent à d'autres types de besoins (rappelons que notre besoin était ici pontuel pour quelques requêtes spécifiques) mais ceci est une autre histoire :-). Bon scrap !
Merci à Olivier et Sébastien !
Pour le XPath, autre formule qui fonctionne :
//div[3]/div[2]/div/div/div/div/div/div/div
Configurez les colonnes comme expliqué dans le tuto de Sébastien 🙂
Pour les curieux, un autre outil à tester, DataMiner. Même si Scraper, c’est top 🙂
Salut Olivier et merci pour le lien 😉
Il est vrai que pour du scrap occasionnel (et sur Google), les solutions proposées sont tout à fait adéquates. Après comme tu le dis à la fin de ton article, pour du scrap un peu plus efficient et surtout pour récupérer les données que l’on souhaite, il faudra effectivement se tourner vers des outils plus spécifiques (non non, pas de pub ^^).
Mais comme tu le dis si bien : « ceci est une autre histoire 🙂 »
P.S. : N’hésites pas à nous contacter si tu as des besoins plus spécifiques ou si tes besoins en scrap deviennent moins occasionnels 😉
Très bonne astuce ! J’utilise Xpath pour scraper pas mal de choses aussi, mais je ne connaissais pas ces deux outils. Merci pour le partage
A vrai dire, j’avais cité Yooda Insight initialement puis je l’ai retiré car il ne te permet pas (à priori) d’importer une liste de KW pour en extraire les données. Cela dit, c’est un excellent outil, que j’utilise au quotidien.
@Stéphane c’est nettement plus compliqué car cela implique d’aller effectuer une requête par mot-clé. Et Google affiche rapidement un captcha dans ce cas (il faut donc passer par des proxies). RDDZ Scraper peut néanmoins convenir. Personnellement j’utilise ZennoPoster.
@Cédric : merci de ta réponse. J’ai jeté un oeil aux deux solutions, les deux sont intéressantes, et en élargissant mes recherches (et quelques tests), j’ai finalement retenu Yooda Insight (outil Keyword Suggest) pour l’analyse de la concurrence. Mais ça n’enlève rien à l’utilité du tutoriel ci-dessus et des solutions dont tu as parlé : merci ! 😉
Merci Olivier,
J’utilise parfois la bar Moz et je ne m’étais jamais rendu compte de cette possibilité ^^
Comme quoi on en apprend tous les jours 🙂
Bonjour, merci pour ce tuto, très intéressant. Existe-t-il un outil qui permette d’obtenir le nombre de résultats du moteur de recherche selon une liste de mots clefs ?
Merci beaucoup,
Je vais essayer ces astuces pour gagner du temps
Comme toujours merci Abondance !
Non en effet, cette donnée n’était pas présente dans le document. C’est corrigé si tu veux aller tester (version 2.0) 🙂
J’avais vu ton outil dans mes recherches mais l’absence de descriptif m’avait fait chercher ailleurs. Corrigé donc 🙂 Merci !
Petit moment auto-promo mais ça marche aussi très bien directement dans Excel, ce qui évite le copier-coller
–> http://cedricguerin.fr/scraper-avec-excel/
Je ne vois pas la description dans le fichier proposé ???
Avec mon tuto Olivier tu as bien les données dans des colonnes distinctes si tu utilises les expressions Xpath spécifiées dans la section « Columns ». Tu peux même extraire à la fois l’url verte (qui est parfois le fil d’ariane) et la vraie URL présente dans l’attribut href 😉
Merci encore Sébastien pour ton aide !