







Pendant longtemps, le fonctionnement des moteurs de recherche a reposé sur une mécanique relativement simple : une requête formulée par l’utilisateur, une page de résultats classée en fonction de critères de pertinence.
L’émergence des moteurs comme ChatGPT, perplexity ou AI Overview bouleverse ce modèle.
Pour produire une réponse, ces moteurs ne se contentent plus d’interroger un index, mais décomposent la question initiale en une multitude de sous-requêtes qu’ils effectuent parfois directement sur… Google !
Ce mécanisme, souvent désigné sous le terme de query fan-out, constitue l’un des fondements techniques de la recherche générative.
Pour mieux comprendre cette évolution, nous avons analysé 102 018 requêtes extraites de notre Outil GEO Qwairy afin d’observer comment elles étaient réellement interprétées et transformées par les moteurs.
Voici 6 apprentissages tirés de cette étude.
Rappel : c’est quoi le Query Fan-Out ?
Le query fan-out est un processus par lequel une seule requête utilisateur (un prompt par exemple) est automatiquement décomposée en plusieurs requêtes secondaires ou sous-requêtes.
Concrètement, si un internaute pose une question complexe, l’IA ne se contente pas d’exécuter une seule recherche : elle lance en parallèle une série de mini-requêtes.
Ces mini-requêtes peuvent être recherchés directement sur Google ou d’autres moteurs de recherche.
Le rôle du Reciprocal Rank Fusion (RRF)
Un élément clé du traitement du query fan-out est le mécanisme de Reciprocal Rank Fusion (RRF), une technique employée pour fusionner plusieurs listes de résultats issues des sous-requêtes en un seul classement final pertinent.
Le principe du RRF repose sur une formule assez simple mais puissante : chaque source ou document obtient un score basé sur sa position dans chaque liste de résultats. Plus une page apparaît souvent, même à des rangs variés, plus son score cumulé augmente ; elle est donc considérée comme plus pertinente globalement.
Vous pouvez jeter un oeil à cet article pour mieux comprendre le RRF.
Par exemple :
- Une page qui apparaît en position 1 sur une sous-requête mais absente sur les autres aura un score inférieur à une page qui apparaît en positions 3, 4 et 5 sur plusieurs sous-requêtes différentes.
- Grâce à cette addition des scores, le moteur parvient à retenir des sources solides et cohérentes sur l’ensemble du spectre des sous-requêtes générées, et pas seulement celles qui “cliquent” sur une seule formulation de la recherche.
102 018 requêtes analysées : la data exclusive de Qwairy
Pour éclairer la manière dont les moteurs IA décomposent et traitent les requêtes, l’étude dont nous nous inspirons ici a été conduite par l’équipe de recherche de Qwairy.
L’étude se base sur un ensemble de 102 018 requêtes générées sur des systèmes d’IA, issues de 38 418 prompts utilisateurs distincts, recueillies entre septembre et novembre 2025.
Toutes ces requêtes proviennent des interactions entre des utilisateurs et des solutions d’IA, telles que ChatGPT et Perplexity, analysées via la plateforme de Qwairy pour observer précisément la manière dont chaque moteur réagit à une demande.
Apprentissage n°1 - Le Provider Effect est massif : tous les moteurs IA ne pratiquent pas le query fan-out de la même façon
L’un des enseignements les plus structurants de l’analyse menée par Qwairy concerne ce que nous appelons le Provider Effect.
L’étude Qwairy, basée sur 102 018 requêtes issues de 38 418 prompts utilisateurs, montre une fracture très nette entre deux grandes approches de la recherche IA :
- Perplexity adopte majoritairement une logique de recherche simple et directe
→ 70,5 % des prompts génèrent exactement une seule requête “fan-out”
- ChatGPT, à l’inverse, privilégie une logique exploratoire
→ seulement 32,7 % des prompts génèrent une seule requête “fan-out”
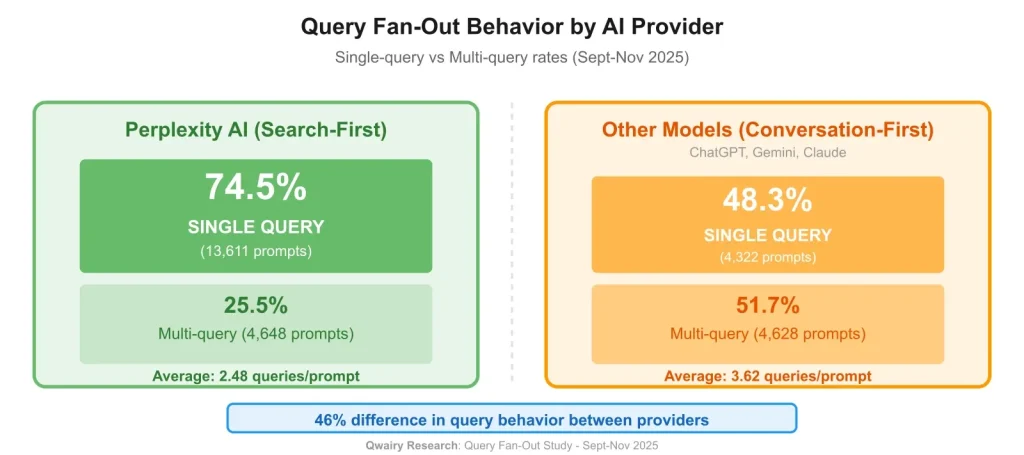
Autrement dit, ChatGPT a deux fois plus tendance que Perplexity à fragmenter une requête utilisateur en plusieurs sous-requêtes.
Apprentissage n°2 - L’effet multiplicateur
L’analyse des données Qwairy montre que ce mécanisme produit un véritable effet multiplicateur : une seule requête utilisateur peut générer plusieurs opportunités de visibilité, à condition que le moteur IA explore effectivement plusieurs requêtes.
Quand une requête devient cinq (ou plus)
Les données observées indiquent que, lorsque ChatGPT déclenche un fan-out, il ne se limite pas à deux ou trois variantes.
Sur des requêtes de type “best”, “top”, “list” ou “comparison”, le moteur génère en moyenne plus de cinq sous-requêtes distinctes pour un seul prompt utilisateur.
Prenons un exemple simple :
“best project management tools”
Dans ce cas, ChatGPT va typiquement interroger le web via plusieurs formulations :
- comparaisons générales,
- listes d’outils,
- classements récents,
- variantes incluant l’année en cours,
- parfois même des angles sectoriels implicites.
Pour une marque ou un contenu, cela signifie une chose très claire :
👉 apparaître dans une seule requête ne suffit plus.
👉 être présent dans plusieurs variantes augmente mécaniquement les chances d’être sélectionné comme source finale.
C’est précisément ce que l’on appelle ici l’effet multiplicateur du query fan-out.
Voici un exemple sur les agences RGPD (en anglais) :

Un effet… qui n’existe pas partout
Mais - et c’est un point crucial - cet effet multiplicateur n’est pas universel.
L’étude Qwairy montre clairement que :
- ChatGPT, qui pratique largement le fan-out, bénéficie pleinement de cet effet RRF
- Perplexity, qui génère une seule requête dans 70,5 % des cas, ne déclenche quasiment aucun effet multiplicateur
Apprentissage n°3 - Les mots déclencheurs du query fan-out sont largement prévisibles
L’un des enseignements les plus opérationnels de l’étude menée par Qwairy concerne l’identification de mots et formulations qui déclenchent mécaniquement un fort query fan-out.
Certains termes font basculer les moteurs en mode exploration
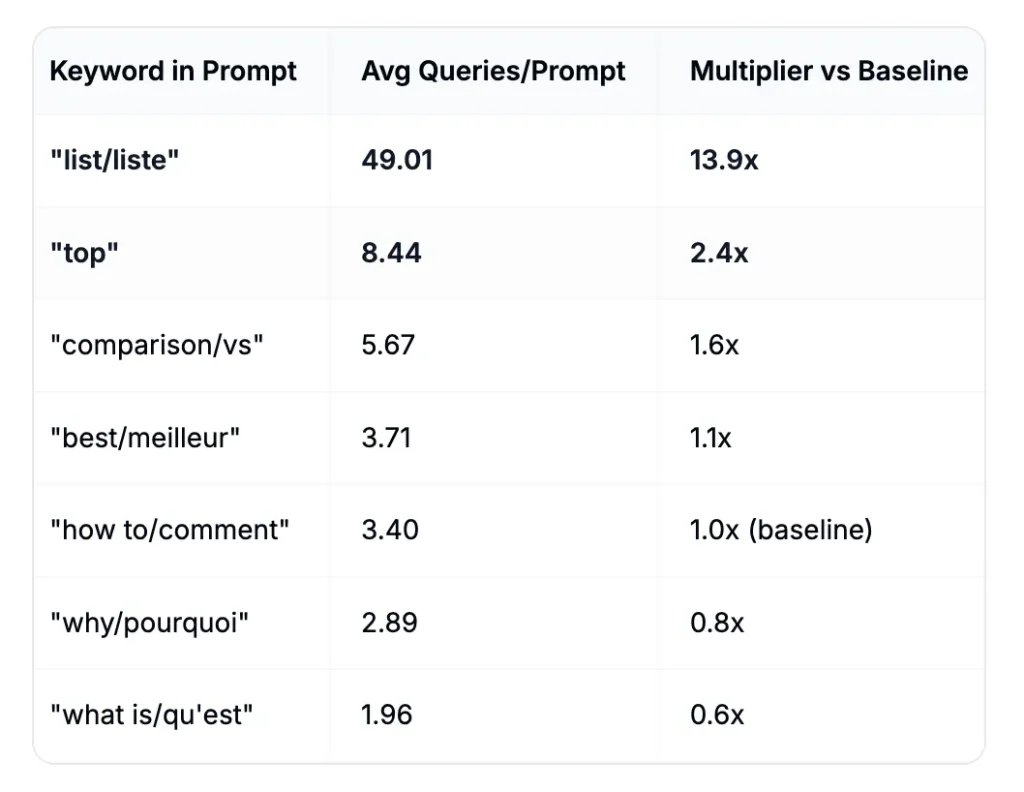
L’analyse des 102 018 requêtes générées par les IA montre que certains mots présents dans les prompts utilisateurs entraînent une augmentation massive du nombre de requêtes internes.
Parmi les plus marquants :
- “List” → 49,01 requêtes en moyenne
(soit environ 14 fois le niveau de base)
- “Top” → 8,44 requêtes en moyenne
(2,4 fois le niveau de base)
- “Comparison” / “vs” → 5,67 requêtes en moyenne
(1,6 fois le niveau de base)
Pourquoi ces mots déclenchent-ils autant de fan-out ?
Pour un moteur IA, une requête comme “best tools” ou “top solutions” soulève immédiatement plusieurs questions secondaires :
- quels critères définissent le “meilleur” ?
- quels outils sont cités de manière récurrente ?
- existe-t-il des variations selon l’usage, le secteur ou la localisation ?
- les résultats sont-ils à jour ?
Plutôt que de tenter de répondre à toutes ces questions à partir d’une seule requête, l’IA choisit de les fragmenter, d’où l’explosion du nombre de sous-requêtes observées dans les données Qwairy.
Apprentissage n°4 - L’IA ajoute systématiquement des mots-clés que l’utilisateur n’a jamais tapés
L’un des résultats les plus surprenants - et pourtant les plus structurants - de l’étude Qwairy concerne la manière dont les moteurs IA enrichissent automatiquement les requêtes utilisateurs.
Contrairement aux moteurs traditionnels, l’IA ne se contente pas de reformuler une question : elle ajoute activement des éléments contextuels jugés nécessaires pour produire une réponse pertinente.
Des ajouts invisibles, mais massifs
L’analyse des 102 018 requêtes générées montre que, dans une proportion significative des cas, les moteurs IA introduisent des termes absents du prompt initial :
- Ajout de l’année en cours
→ “2025” est ajouté dans 28,1 % des requêtes
- Ajout de signaux géographiques
→ “France” dans 13,9 % des cas
→ “Paris” dans 5,1 % des cas
- Ajout de termes évaluatifs
→ “meilleur” dans 16,7 % des requêtes
→ “best” dans 5,9 % des requêtes
Ces enrichissements ne sont pas anecdotiques : ils modifient profondément la nature des requêtes réellement exécutées par l’IA.
Apprentissage n°5 - Des requêtes… rarement identiques d’une fois sur l’autre
Autre enseignement clé de l’étude Qwairy : la variabilité des requêtes générées.
- Sur ChatGPT, 89 % des prompts identiques conduisent à des requêtes différentes d’une exécution à l’autre.
- Sur Perplexity, à l’inverse, 93 % des prompts génèrent exactement la même requête fan-out.
Cette différence renforce les constats précédents :
- ChatGPT privilégie une logique adaptative, contextuelle et exploratoire ;
- Perplexity vise la stabilité et la reproductibilité.
Apprentissage n°6 - Le query fan-out ne change pas le SEO partout (et c’est une bonne nouvelle)
L’un des risques lorsqu’on aborde la recherche à l’ère des moteurs IA est de tomber dans une vision uniformisante : l’idée que toutes les requêtes seraient désormais traitées via un query fan-out massif, rendant obsolètes les pratiques SEO classiques.
Les données issues de l’étude Qwairy montrent une réalité bien plus nuancée.
Tous les sujets ne déclenchent pas le même niveau de fan-out
L’analyse des 38 418 prompts utilisateurs révèle une distinction très claire entre deux grandes catégories de requêtes :
- Les requêtes à faible fan-out, souvent informationnelles, factuelles ou explicatives
→ “why”, “pourquoi”, “what is”, définitions, questions précises
Cela signifie simplement que l’IA a la réponse dans sa base de donnée et n’a pas besoin de chercher des informations en ligne.
- Les requêtes à fort fan-out, majoritairement évaluatives ou décisionnelles
→ “top”, “best”, “list”, comparaisons, agences, outils, services locaux
Dans le premier cas, l’IA génère peu de sous-requêtes, parfois une seule. Dans le second, elle entre en mode exploration, multipliant les requêtes pour couvrir un espace informationnel plus large.
Quand la couverture devient déterminante
À l’inverse, sur les sujets à fort fan-out, la logique s’inverse :
- la requête utilisateur est perçue comme ambiguë ou multidimensionnelle,
- l’IA cherche à comparer, recouper, valider,
- la visibilité dépend de la capacité à apparaître dans plusieurs déclinaisons du même besoin.
C’est typiquement le cas pour :
- les classements (“top 10”, “meilleurs outils”),
- les comparatifs,
- les recommandations de prestataires ou de solutions,
- les recherches locales à enjeu commercial.
Dans ces environnements, se positionner sur une seule requête ne suffit plus : la couverture thématique devient un avantage concurrentiel réel.
Une conséquence stratégique essentielle
Cet apprentissage permet de dépasser une vision du SEO à l’ère de l’IA.
Le query fan-out ne rend pas toutes les stratégies obsolètes : il segmente les efforts.
👉 La bonne question n’est donc pas :
« Faut-il adapter toute sa stratégie SEO au query fan-out ? »
👉 Mais plutôt :
« Sur quels types de requêtes le query fan-out est-il réellement activé ? »
En identifiant les thématiques à fort fan-out, les équipes SEO peuvent concentrer leurs efforts là où ils ont le plus d’impact, tout en conservant des approches plus traditionnelles sur les sujets à faible fan-out.






