







Une petite mise au point sur des possibilités de mauvaise interprétation du message, dans les résultats de Google, indiquant qu'une page web est interdite de crawl par un fichier robots.txt...
Le 20 août dernier, nous vous signalions que Google indiquait dans ses résultats lorsqu'une page était bloquée par un fichier robots.txt sous la forme du texte "A description for this result is not available because of this site’s robots.txt – learn more" (en français : "La description de ce résultat n'est pas accessible à cause du fichier robots.txt de ce site. En savoir plus") comme représenté ci-dessous :
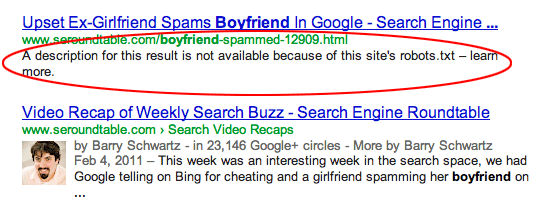 Source de l'image : Search Engine Land |
Certains (notamment ici) ont pu croire, à la lecture de cette actualité, que Google crawlait des pages qui étaient pourtant interdites à cette action au travers du fichier robots.txt. Soyons clair : il n'en est rien : avant qu'un message soit affiché sous la mention indiquée ci-dessus, les résultats de ce type affichaient l'URL de la page (ou un texte plus explicite parfois) comme titre et aucun "snippet" (texte de présentation) comme ici :
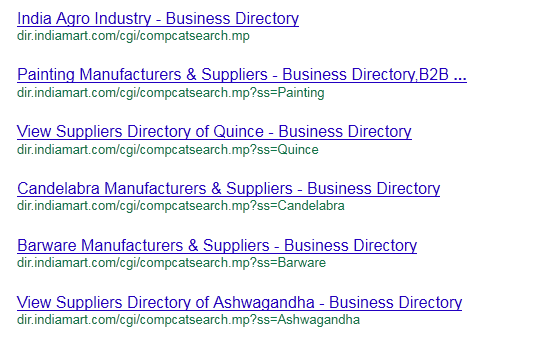 Source de l'image : DEE-ESS |
Cela signifie que Google connait les pages en question (il a notamment détecté un lien vers elles) mais, comme elles sont interdites au crawl, il ne connait pas leur contenu et ne peut donc pas en proposer un "snippet". Le titre proposé est la plupart du temps issu d'un texte d'ancre pointant sur la page en question.
Il est donc clair que ces pages ne sont pas crawlées ni analysées par les moteurs de recherche. La véritable question est en revanche l'intérêt de les faire apparaître dans les résultats de recherche au vu du faible intérêt qu'elles représentent (comme content is king, difficile de briguer le trône quand il n'y a pas de "content" !!). Il me semble me souvenir que Google avait indiqué, il y a quelques années de cela, que ces URL apparaissaient de façon transitoire, entre le moment où Google les a détectées (via un lien vers elles) et celui où il s'aperçoit qu'elles sont interdites de crawl par un robots.txt.
Ce qui ne semble plus valable puisque Google affiche désormais un message explicite à propos du robots.txt. Dans ce cas, pourquoi ne pas les désindexer purement et simplement ??





@ François-Olivier @Olivier les pages sont crawlées puisque le title (exact) de la page bloqué apparaît dans les SERP …
Les pages interdites d’indexation par le robots.text sont bien repérées comme telles par Google et figurent dans les réponses à des requêtes avec le message signalant le blocage du contenu.
On peut y accéder en cliquant sur le lien qui apparaît clairement avec son URL!!…Elles sont donc indexées chez Google et accessibles à partir des serp
Ces liens vers des pages que l’on souhaite éliminer de l’index, pour éviter par exemple qu’elles viennent concurrencer des pages plus pertinentes, subsistent dans les SERP et le blocage est donc partiellement inefficace.
Ce n’est pas par ce que le « snippet » a été remplacé par le message d’information que l’on évitera le fait qu’un internaute clique sur le lien apparent en clair et actif.
Google reconnait lui-même que si un lien provenant d’un autre site pointe vers une page « bloquée », le lien peut apparaître dans les SERP avec probablement le texte d’ancre comme description..
Si une page reçoit beaucoup de liens de sites extérieurs avec des textes d’ancre variés, on retrouvera dans les serp plusieurs liens vers cette page « bloquée » à avec plusieurs descriptions
En conclusion, les contenus complets des pages ne sont peut-être pas indexés et ne servent peut-être pas à Google pour ses analyses de positionnement, mais les url « bloquées » sont bien là dans les serp et accessibles depuis les serp. Le « blocage » est bien partiel.
Bonjour,
J’ai mis en ligne mon site via WIX il y a 5 jours et je ne vois toujours pas le descriptif de mon site dans google. Quand je rentre le nom de mon site.com dans Google, j’ai exactement ce message d’erreur :
pas accessible à cause du fichier robots.txt de ce site
Que faire pour que Google n’interdise pas la description de mon site et qu’il soit pris en compte dans les moteurs ?
merci pour vos lumières !
Google recommande d’utiliser la méta balise noindex plutôt que le fichier robots.text pour éviter le problème
Olivier,
Ne pensez vous pas qu’il y a un bug du moteur de recherche ? Cela me surprend qu’ils laissent trainer ce type d’erreur
Bonjour,
merci Olivier pour cette info.
La page n’est pas indexée, mail l’URL l’est en quelque sorte ?
Comment sont stockées ces URL bloquées, ce n’est pas l’index, c’est l’ordonnanceur ? Ce je comprends mal, c’est que les SERP sont une vue de l’index…?
Merci de vos lumières.
Cela signifie que si l’on veut cacher une page à Google et donc aux internautes, le robots.txt ne sert plus à grand chose… Mieux vaut un accès sécurisé par login/mot de passe ! C’est un peu comme si Google disait « Regardez cette page à laquelle on m’a interdit l’accès »
Google devrait faire attention à ses propres produits car cette absence de description n’est pas du meilleur effet au niveau marketing. Exemple sur une recherche « Google Drive », le premier résultat est :
Google Drive – Drive – Google
https://drive.google.com/start
La description de ce résultat n’est pas accessible à cause du fichier robots.txt de ce site. En savoir plus
Mais dans ce cas, c’est quand même mieux d’avoir un résultat plutôt que pas de résultat, donc pour moi la balance penche du côté de l’affichage même partiel lorsque la page est bloquée par un robots.txt
Je crois que cet article fais suite à l’article de Daniel Roch sur SEOmix.
Donc Google ne crawl pas ces pages mais les affiche dans ces résultats. Bizarre …
@ François-Olivier : oui nouveaux tests en cours… Et comme j’ai aussi reçu pas mal d’infos à ce sujet de la part de Google (comment le moteur prend en compte le robots.txt), il faut s’attendre à un nouvel article sur ce sujet d’ici peu de temps sur Abondance. 🙂
cdt
On attend vivement la suite de cet article.
Mélanie
Bonjour,
Tu dis qu’il est « Il est donc clair que ces pages ne sont pas crawlées ni analysées par les moteurs de recherche. » As tu des preuves et fais des tests pour être aussi catégorique ?
Pas présentée est une chose, pas crawlée s’en est une autre.
Je suis pour la non indexation radicale de toutes les pages qui ne sont pas d’une qualité (de contenu) suffisante : d’ailleurs, mieux vaut se concentrer sur l’obtention de (très) bons résultats sur qq pages clés que de viser trop large. Allez, j’entends déjà les fans de la longue traîne hurler à la mort…
Google ne met pas ses propres DOCS à l’abri
ou alors il nous donne des vieux os à ronger
Merci à @5eg
https://twitter.com/5eg/statuses/242960778796355584
David
Son intérêt doit être de tout montrer, sans doute
mais alors, s’il trouve un doc sur DRIVE, il met le lien (protégé mais montrant l’existence tout de meme) ????
Notre intérêt est de ne rien mettre en ligne si on veut le cacher. (et je ne suis pas sûr d’avoir respecté cette rêgle).
Nos pratiques CLOUDY seraient alors un vrai danger pour nous.
David
Je me suis posé la même question, d’autant qu’il me semble simple de procéder a l’inverse lors d’un suivis de lien, c’est a dire de faire sonder au robot le cas possible d’un blocage par fichier robots.txt ou pas, et d’indexer le lien ou pas en fonction.
le probleme, c’est que google tombe sur un lien contenant un login ou mot de passe, ou des informations privées, et que du coup, celles-ci soient publiées.
Cette annonce confirme que le robots de Google fait plusieurs passes pour analyser un site, mais cela, on le savait déjà.