






Google a annoncé la semaine dernière qu'il commençait à utiliser de façon significative l'OCR (Optical Character Recognition pour Reconnaissance Optique de Caractères) pour scanner des documents papier afin de reconnaître les textes qui y étaient imprimés. Tout document papier ainsi reconnu devient alors un document numérique "comme un autre", susceptible d'apparaître dans les pages de résultats du moteur de recherche.
Les résultats sont alors présentés sous la forme d'un fichier PDF, la version originale étant visualisable grâce au lien "View as HTML" :
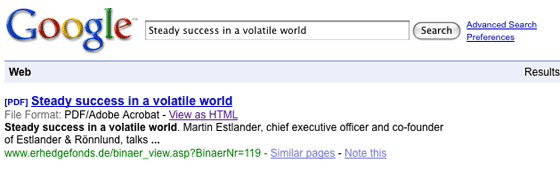  Source de l'image : Google |
Plus d'infos :
http://www.google.com/
Source(s) :
A picture of a thousand words? (Google)
Articles connexes sur ce site :
- Google lorgne vers l'OCR (13 septembre 2006)
- Un brevet sur la reconnaissance de textes dans les images et les vidéos pour Google (7 janvier 2008)
Toutes les pages du réseau Abondance pour la requête ocr...
Toutes les pages du Web pour la requête ocr...




C'est une bonne îdée d'enrichir la biblio google docs, mais ma question se pose sur compatiblité de l'OCR avec les docs en langue arabe.
Oui enfin cela était déjà effectif pour du PDF texte, parce que les images ne sont toujours pas interprétées.
Globalement, un PDF peut être accessible mais ne permettra jamais de structurer le contenu. Il ne faut pas oublier à quoi il sert : à être imprimer. Son utilisation comme format d’échange est une hérésie.
Cela pose plein de questions:
* les référneceurs devront-ils donc commencer par apprendre à leurs client à utiliser word correctement: (remplir les méta-données, utiliser des structures de titres documents propres (pas de gras grossi, mais l’arborescence des menus automatqiue ?)
* comment faire retirer un document par Google ?
* les documents resteront-ils en cache ? Si oui.. hébergé par qui?
* apparition de balises nofollow et noindex dans les formats de documents bureautique ?
Qu’en pensez-vous Olivier?