







Google vient d’annoncer MUVERA, un nouvel algorithme de recherche qui pourrait changer en profondeur la manière dont le moteur traite les requêtes complexes. Son objectif : allier la puissance des modèles multi-vecteurs, capables de comprendre finement le sens des mots et des contextes, à la rapidité des recherches classiques sur vecteur unique. Voici notre décryptage d’une avancée qui pourrait bien remodeler l’univers du SEO et des systèmes de recommandation.
Ce qu'il faut retenir :
- MUVERA transforme la recherche multi-vecteurs en recherche sur vecteur unique, grâce à une technique de Fixed Dimensional Encoding (FDE).
- Des performances largement améliorées, avec jusqu’à 90 % de réduction de la latence par rapport aux anciens systèmes comme PLAID.
- Vers un SEO plus contextuel : l’algorithme privilégie la compréhension sémantique plutôt que le simple matching de mots-clés.
- Une solution adaptée aux grandes échelles, potentiellement exploitable dans la recherche web, les systèmes de recommandation comme YouTube et le traitement du langage naturel.
Comprendre le contexte : pourquoi MUVERA ?
Depuis une dizaine d’années, la recherche d’information (IR) a fait un bond grâce aux modèles dits d’embeddings neuronaux. Ces modèles traduisent textes, images ou vidéos en vecteurs numériques. Leur principe : des contenus sémantiquement proches (par exemple « Le Roi Lear » et « tragédie de Shakespeare ») se retrouvent géographiquement proches dans un espace mathématique. Ainsi, au lieu de simplement compter les mots communs, on évalue la similarité sémantique.
Jusqu’ici, la plupart des systèmes de recherche modernes utilisaient des représentations à vecteur unique. Chaque document ou requête est résumé dans un seul vecteur, ce qui permet une recherche rapide via des techniques comme le Maximum Inner Product Search (MIPS), un algorithme optimisé pour comparer rapidement ces vecteurs.
Mais un problème demeure : ces vecteurs uniques restent parfois trop grossiers pour saisir toute la richesse d’un texte. C’est là qu’interviennent les modèles multi-vecteurs comme ColBERT, qui créent plusieurs vecteurs par document ou requête (souvent un par token). Résultat : une compréhension bien plus fine des relations sémantiques internes. Seul hic : cette finesse a un coût, car comparer plusieurs vecteurs entre eux (via des techniques comme le Chamfer similarity) est extrêmement gourmand en calcul.
MUVERA : la solution signée Google
L’algorithme MUVERA, récemment dévoilé par Google Research, propose un compromis astucieux : conserver la richesse des modèles multi-vecteurs, tout en ramenant la complexité de la recherche au niveau des modèles à vecteur unique.
Son secret : une technique baptisée Fixed Dimensional Encoding (FDE). Plutôt que de manipuler directement tous les vecteurs d’un document ou d’une requête, l’algorithme MUVERA les « condense » en un seul vecteur. Et ce vecteur unique est construit de façon à reproduire au mieux la similarité qu’on obtiendrait si on comparait l’intégralité des vecteurs multi-vecteurs d’origine.
Concrètement, voici comment ça fonctionne sur le plan technique :
- Génération des FDEs
- Chaque token est tout d’abord transformé en vecteur haute dimension.
- L’espace vectoriel est ensuite découpé en zones via des hyperplans aléatoires.
- Pour une requête, on additionne les vecteurs tombant dans chaque zone.
- Pour un document, on fait plutôt une moyenne dans chaque zone, pour respecter la nature asymétrique de la similarité Chamfer (qui mesure combien chaque partie de la requête est présente dans le document).
- Recherche rapide via MIPS
Une fois toutes les FDEs générées, la recherche se fait via un simple MIPS sur ces vecteurs condensés. Cela permet d’utiliser l’infrastructure existante ultra-optimisée des moteurs de recherche, sans avoir à comparer tous les sous-vecteurs entre eux. - Re-ranking
Les meilleurs candidats trouvés sont ensuite recalculés avec la véritable Chamfer similarity pour affiner la précision.
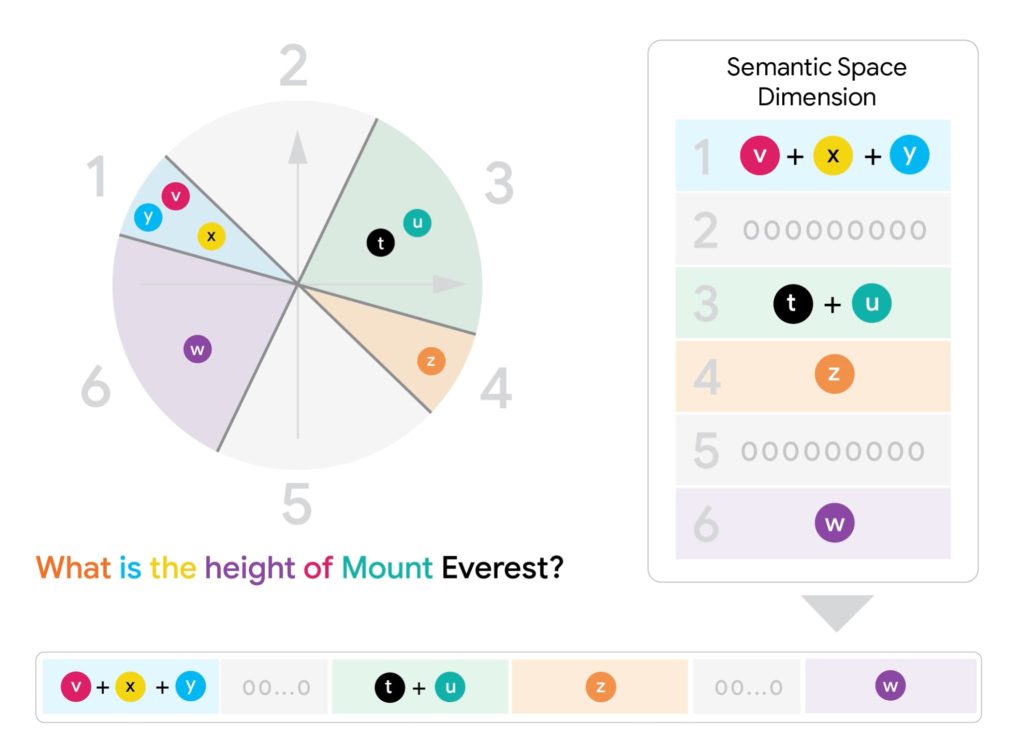
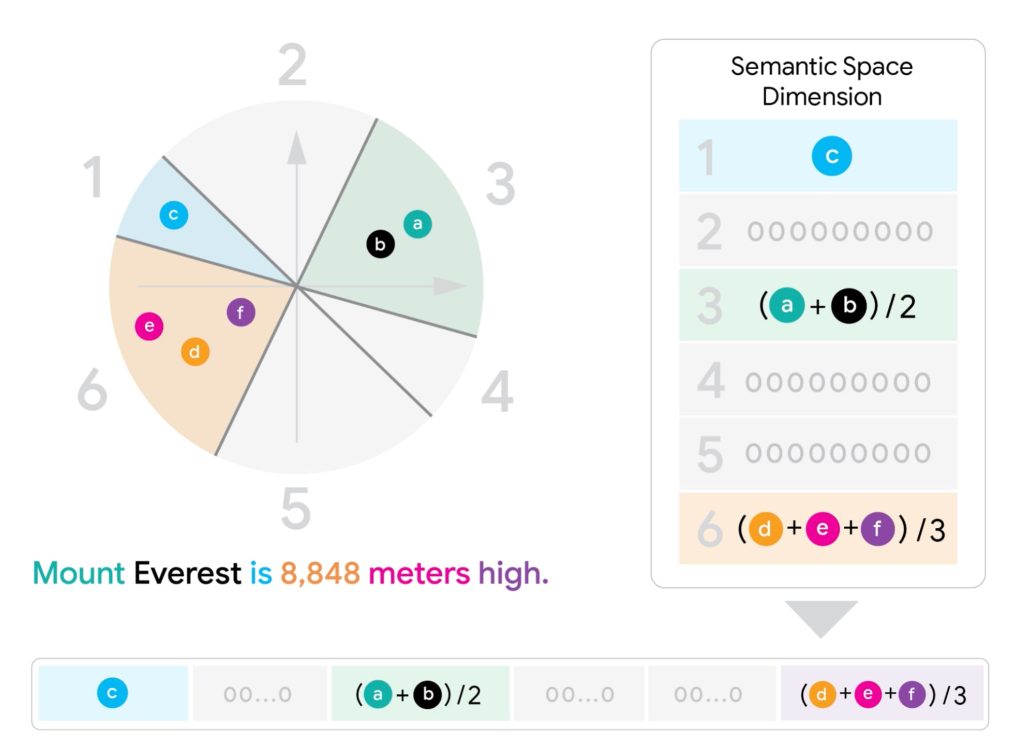
Les gains de performance de MUVERA
Les résultats sont impressionnants. Sur les benchmarks BEIR, MUVERA est parvenu à :
- Réduire la latence de 90 % par rapport à PLAID, l’un des systèmes multi-vecteurs les plus performants jusqu’alors.
- Améliorer le rappel de 10 % en moyenne, tout en examinant 5 à 20 fois moins de documents pour un même niveau de précision.
- Réduire la taille mémoire grâce à la compression des FDEs via des techniques comme la Product Quantization, divisant la mémoire par 32 sans perte notable de qualité.
Pour résumer, ces performances font de MUVERA une solution enfin viable pour intégrer le multi-vecteur dans des systèmes à grande échelle, comme la recherche web ou la recommandation sur des plateformes géantes comme YouTube.
Quelles conséquences pour le SEO et la recherche ?
MUVERA illustre parfaitement la mutation de la recherche vers des modèles sémantiques profonds. Là où le SEO traditionnel se concentrait sur les mots-clés et leurs variations exactes, la logique multi-vecteur (et donc MUVERA) s’intéresse au sens global des requêtes et à leur contexte.
Pour les professionnels du SEO et les éditeurs de sites, cela signifie :
- Moins de place pour les astuces basées sur des mots-clés exacts.
- Plus d’importance accordée au contenu réellement pertinent pour l’intention de recherche.
- Une meilleure capacité à traiter les requêtes dites « tail », moins fréquentes mais souvent plus spécifiques, grâce à la précision des modèles multi-vecteurs.
En clair, MUVERA pourrait marquer un tournant vers une recherche encore plus contextuelle, où comprendre la nuance d’une question devient essentiel pour apparaître dans les premiers résultats.
Google n’a pas confirmé si MUVERA était déjà en production dans le domaine de la recherche web. Mais au vu des performances annoncées et de son intégration possible dans l’infrastructure existante, il est probable que cette technologie ou ses déclinaisons jouent bientôt un rôle clé dans la manière dont le moteur répond à nos requêtes les plus complexes.
 l’algorithme Google")





