







Les sites web ont appris à parler aux navigateurs, puis aux moteurs de recherche. Cloudflare estime qu'ils doivent désormais apprendre à parler aux agents IA, et lance un outil pour les y aider. Une initiative ambitieuse, mais qui soulève autant de questions qu'elle n'en résout.
Ce qu'il faut retenir :
- Cloudflare lance isitagentready.com, un outil gratuit qui attribue un score d'optimisation aux sites web selon leur compatibilité avec les agents IA, sur quatre dimensions : découvrabilité, contenu, contrôle d'accès, et capacités.
- Le web est loin d’être prêt : seulement 4 % des 200 000 sites analysés déclarent leurs préférences d'usage par les IA, et moins de 15 sites ont adopté les standards les plus récents comme MCP Server Cards ou API Catalogs.
- L'initiative s'appuie sur un écosystème de standards en cours de construction, ce qui expose les adoptants précoces à des risques de fragmentation ou d'obsolescence rapide.
- Cloudflare est à la fois arbitre du score et fournisseur de solutions pour l'améliorer, une position qui mérite d'être questionnée.
Un outil de notation pour un problème réel
Le point de départ de Cloudflare est solide. Quand un agent IA comme Claude, Cursor ou OpenCode tente d'accéder à un site web pour y lire de la documentation, acheter un produit ou interagir avec une API, il se retrouve face à une infrastructure pensée pour des humains : du HTML dense, des formulaires, des sessions de navigation, des captchas. Le résultat, c'est des agents lents, coûteux en tokens, et souvent inexacts.
Pour mesurer l'ampleur du problème, Cloudflare a scanné les 200 000 domaines les plus visités du web, en filtrant les redirecteurs, serveurs publicitaires et services de tunneling pour se concentrer sur les sites avec lesquels les agents pourraient raisonnablement interagir.
Le bilan est édifiant : 78 % des sites ont un fichier robots.txt, mais la quasi-totalité d'entre eux a été écrite pour les crawlers de moteurs de recherche traditionnels, pas pour des agents. Seulement 3,9 % des sites servent du contenu en Markdown quand on le leur demande. Et les standards émergents comme les MCP Server Cards sont présents sur moins de 15 sites dans l'ensemble du dataset.
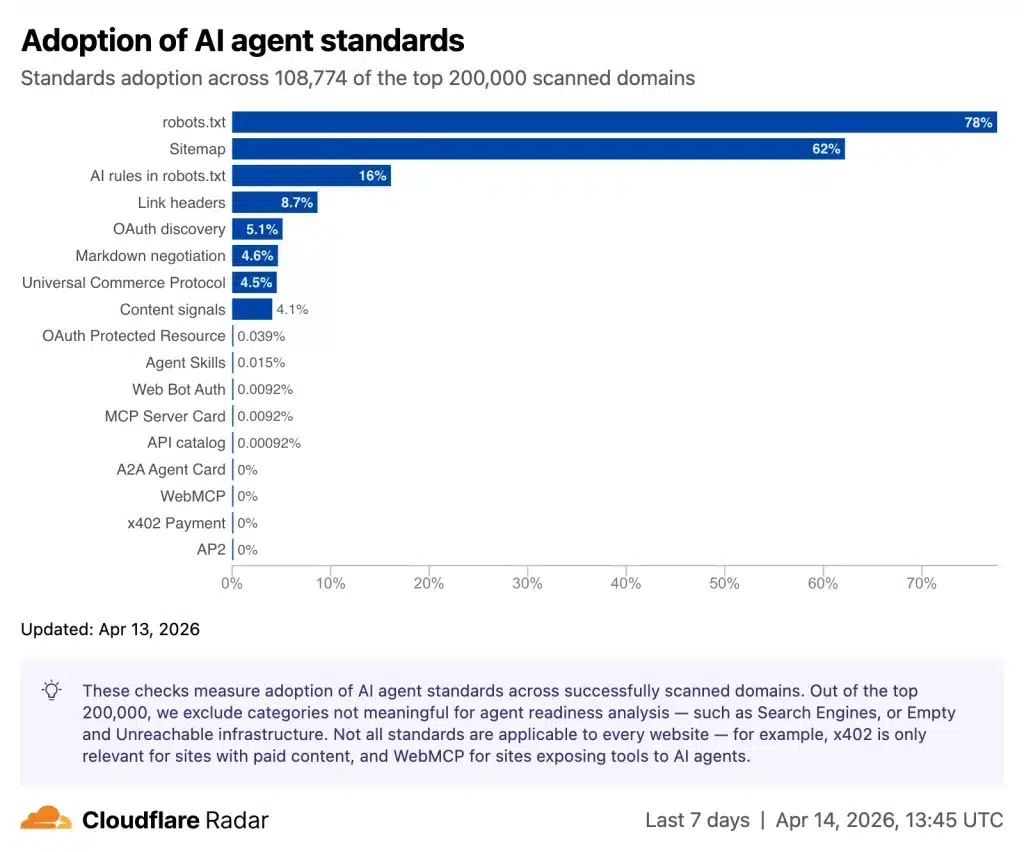
Dévoilée par Cloudflare, la solution isitagentready.com propose alors un score structuré autour de quatre axes.
- La découvrabilité (discoverability) vérifie la présence et la qualité du
robots.txt, d'unsitemap.xml, et des Link Headers. - Le contenu (content) évalue si le site sait servir une version Markdown propre à la demande d'un agent.
- Le contrôle d'accès (bot access control) regarde si le site exprime des préférences claires sur ce que les IA peuvent faire de son contenu.
- Enfin, les capacités testent la présence de standards plus avancés comme les MCP Server Cards, l'API Catalog, ou la découverte OAuth pour que les agents puissent s'authentifier proprement.
Des standards encore balbutiants et une adoption quasi nulle
C'est ici que l'enthousiasme de Cloudflare doit être tempéré. Plusieurs des standards mis en avant dans ce score sont soit en cours de rédaction à l'IETF, soit des propositions informelles sans garantie d'adoption généralisée. L'API Catalog (RFC 9727), les MCP Server Cards, ou encore le Web Bot Auth sont des standards récents dont certains n'ont pas encore atteint le statut de RFC définitive au moment de la publication.
Cette situation n'est pas propre à Cloudflare : c'est la réalité d'un web en phase d'évolution. Mais elle impose une honnêteté que le billet de blog de Cloudflare tend à minimiser. Adopter aujourd'hui un standard qui sera remanié ou abandonné dans dix-huit mois, c'est potentiellement s'engager dans un travail d'intégration qui devra être refait. Les grands acteurs, qui ont les ressources pour suivre ces évolutions, s'y retrouveront. Les équipes réduites ou les développeurs indépendants, moins.
Le cas du llms.txt est illustratif. Proposé en septembre 2024, ce fichier standardisé pour présenter un site à un LLM n'est pas inclus par défaut dans le score de Cloudflare, seulement en option. La raison ? Le standard fait encore débat. C'est une décision prudente, mais qui signale que même Cloudflare ne sait pas encore exactement quels paris tenir.
La négociation de contenu en Markdown : un gain réel, mesuré
L'un des aspects les plus concrets de l'initiative, et probablement le plus immédiatement utile, concerne la capacité d'un serveur à répondre en Markdown quand un agent envoie un header Accept: text/markdown. Cloudflare affirme avoir mesuré jusqu'à 80 % de réduction du nombre de tokens nécessaires pour lire une page, par rapport à sa version HTML.
Ce chiffre mérite d'être contextualisé. Le HTML d'une page de documentation technique est souvent très bavard : navigation, menus, scripts, balises imbriquées... tout cela représente du bruit pur pour un LLM. Un fichier Markdown bien structuré, c'est l'essence du contenu sans l'emballage. La conséquence directe, c'est une réduction du coût des appels API pour les agents, une réduction de la latence, et une meilleure probabilité que l'agent dispose du contexte complet sans tronquer.
Pour illustrer, Cloudflare explique avoir testé son propre site de documentation (developers.cloudflare.com) en pointant un agent (Kimi-k2.5 via OpenCode) sur plusieurs sites techniques. Résultat : 31 % de tokens consommés en moins et des réponses correctes 66 % plus rapides qu'avec d'autres sites non optimisés. Ces chiffres sont à prendre avec précaution, car ils résultent de conditions de test internes non auditées. Mais l'ordre de grandeur est cohérent avec ce que l'on sait du surpoids structurel du HTML.
La mise en oeuvre technique sur Cloudflare Docs : pragmatique et reproductible
La partie la plus instructive du billet est peut-être celle qui décrit comment Cloudflare a remanié sa propre documentation. L'approche est intéressante parce qu'elle contourne un problème réel : en février 2026, seulement trois outils sur sept testés (Claude Code, OpenCode et Cursor) envoient automatiquement le header Accept: text/markdown. Pour les autres, il faut une alternative.
La solution retenue combine deux règles Cloudflare :
- Une réécriture d'URL qui transforme une requête vers
/r2/get-started/index.mden requête vers/r2/get-started/, - Et une transformation de header qui ajoute automatiquement
Accept: text/markdownà ces requêtes réécrites.
Résultat : n'importe quel agent peut accéder à la version Markdown de n'importe quelle page simplement en ajoutant /index.md à l'URL, sans avoir à gérer de header spécial.
Autre décision notable : plutôt qu'un seul fichier llms.txt géant (la documentation Cloudflare compte plus de 5 000 pages), chaque répertoire de premier niveau dispose de son propre fichier, et le fichier racine pointe vers ces sous-répertoires. Cela évite le "grep loop" décrit dans l'article : un agent confronté à un fichier trop long pour tenir dans sa fenêtre de contexte commence à chercher par mots-clés, perd la vue d'ensemble, multiplie les appels et dégrade la qualité de ses réponses.
La granularité a aussi été soignée : environ 450 pages qui ne sont que des listes de liens (pages de répertoire) ont été exclues du llms.txt, puisqu'elles n'apportent aucune valeur sémantique à un LLM dont les pages enfants sont déjà listées individuellement.
Un acteur qui note et qui vend la préparation aux notes
La position de Cloudflare mérite un examen attentif. L'entreprise publie le score de référence pour l'"agent readiness", intègre ce score dans son URL Scanner, propose des prompts prêts à l'emploi pour corriger chaque point de défaillance... et vend les produits (Workers, Rules, Access) qui permettent d'implémenter ces corrections. Le isitagentready.com est lui-même servi par Cloudflare et expose un serveur MCP.
Ce n'est pas forcément problématique : Google a fait la même chose avec Lighthouse et les Core Web Vitals, devenant à la fois juge de la performance et fournisseur d'outils pour l'améliorer (via Google Cloud, Firebase, etc.). Mais cela signifie que les critères du score peuvent évoluer en fonction des intérêts commerciaux de l'entreprise autant que des besoins réels des agents. Un standard porté par une entreprise unique, même avec de bonnes intentions, reste un standard dont les orientations peuvent être infléchies.
Il est aussi notable que Cloudflare pousse activement des standards liés aux paiements agentiques (x402, Universal Commerce Protocol), dont certains impliquent des partenaires directs comme Coinbase. Ces standards ne comptent pas encore dans le score, mais leur présence dans l'outil signale déjà une direction.

Ce que les développeurs peuvent faire concrètement aujourd'hui
Malgré ces réserves, plusieurs actions ont un retour sur investissement clair et immédiat, indépendamment de l'évolution des standards :
- Servir du Markdown à la demande est techniquement simple, réduit les coûts pour les consommateurs de l'API, et améliore la qualité des réponses des agents. C'est la priorité.
- Soigner le
robots.txtpour les agents IA (en ajoutant des directives pour les crawlers commeGPTBot,ClaudeBot,CCBot, etc.) est une bonne hygiène qui ne coûte rien et clarifie les droits d'accès. - Structurer un
llms.txtpar section pour les sites avec beaucoup de contenu est une bonne pratique documentaire qui bénéficie aussi bien aux agents qu'aux humains cherchant à comprendre rapidement l'architecture d'un site.
En revanche, implémenter des MCP Server Cards ou des API Catalogs pour un site qui n'a pas encore d'API publique ou de cas d'usage agent clairement défini reviendrait à construire une salle d'attente avant d'avoir des visiteurs.
L'adoption comme indicateur de marché, pas comme obligation
La vraie valeur de l'initiative de Cloudflare est peut-être dans le dataset Radar qu'elle introduit : un suivi hebdomadaire de l'adoption de chaque standard par les 200 000 sites les plus visités, segmenté par catégorie de domaine. Ce type de donnée permettra de mesurer si les standards "gagnent" réellement, ou bien si la plupart des sites restent passifs en attendant que les agents s'adaptent à eux, comme ils s'adaptent déjà au HTML depuis trente ans.
La réponse à cette question dira beaucoup sur la dynamique de pouvoir entre les éditeurs de sites et les développeurs d'agents. Si les agents les plus populaires finissent par intégrer des capacités de parsing HTML suffisamment robustes, la pression sur les sites pour s'adapter diminuera. Si au contraire les coûts et délais liés à la consommation de HTML non optimisé deviennent un avantage concurrentiel mesurable pour les sites qui s'adaptent, l'adoption suivra naturellement.







